데이터베이스 설계는 시스템 개발을 하기 위해 필수적이기 때문에 데이터베이스 설계가 어떻게 이루어지는지 알 필요가 있다.
데이터베이스 설계는 데이터 중복이 없어야 하며 필요한 데이터에 대한 정확한 분석이 필요하다.
데이터베이스가 제대로 설계되지 않으면 추후 확장이나 유지보수가 굉장히 어렵고, 설계를 바꾸는 작업도 비용이 많이 든다.
( ..데이터베이스 설계가 프로젝트의 백년대계를 좌지우지 한다고 해도 과장이 아니다. )
데이터베이스 설계 프로세스
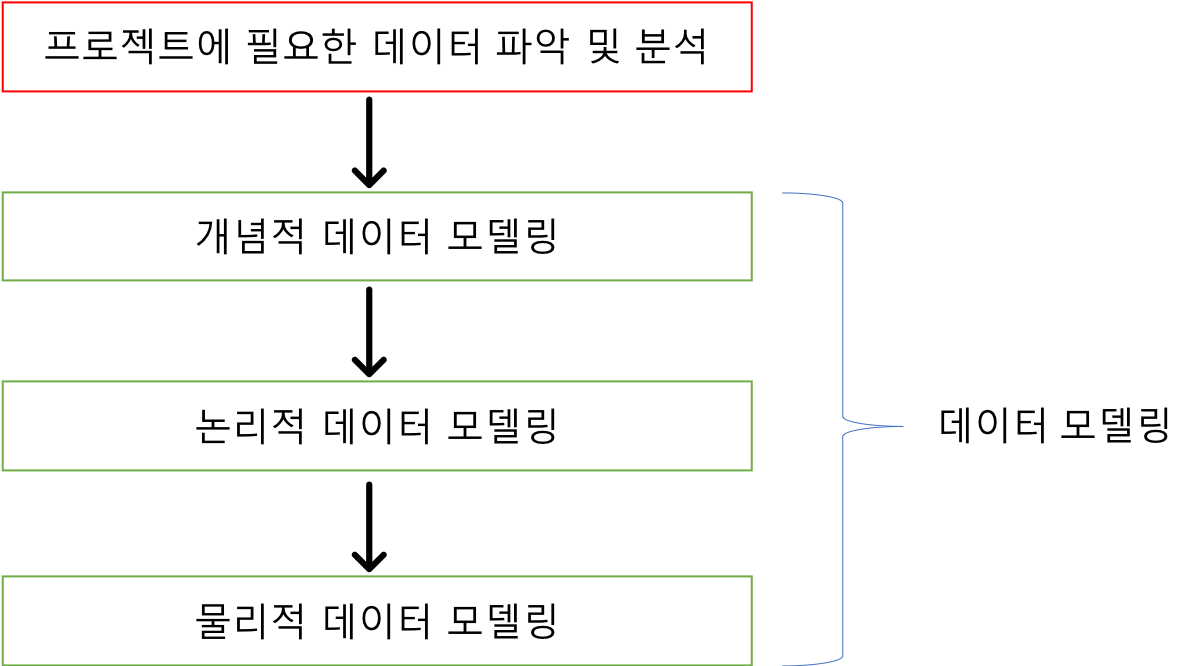
데이터베이스 설계 프로세스를 살펴보면 가장 우선적으로 해야할 일은 프로젝트에 필요한 데이터를 파악하고 분석하는 일이다.
실제로 프로젝트를 진행하다 보면 데이터베이스 설계 자체 문제 보다는 프로젝트에 필요한 데이터에 대한 정의나 파악부터 미흡해서 어려움을 겪는 일이 많기 때문이다.
데이터에 대한 파악과 분석이 끝나면 아래의 그림과 같은 순서로 데이터 모델링을 진행된다.
데이터 모델링이란
데이터 모델링이란 현실 세계의 어떠한 개념을 컴퓨터의 데이터베이스로 옮기는 변환 과정을 의미한다.
이러한 데이터 모델링을 과정에 따라 개념적, 논리적, 물리적 데이터 모델링으로 구분한다.
-
개념적 데이터 모델링
: 개념적 데이터 모델링은 데이터들의 구조도를 그리는 과정이다. 개념적 데이터 모델링을 할 때에는 개체-관계 모델(E-R Model, Entity-Relationship Model)을 많이 사용한다.
-
논리적 데이터 모델링
: 논리적 데이터 모델링은 데이터 모델을 선택하고 데이터 스키마를 결정하는 과정이다. 이 과정에서 관계 데이터 모델을 가장 많이 사용한다.
-
물리적 데이터 모델링
: 물리적 데이터 모델링은 논리적 데이터 모델링에서 선택한 데이터베이스 모델에 따라 데이터베이스 관리 시스템(DBMS)으로 물리적인 데이터베이스를 만들어내는 과정이다.
데이터 모델링 과정이 이름은 어렵게 구분해 놓았지만 단순하게 따져보면 데이터들의 관계를 구조화시켜서 그려보고, 어떤 데이터베이스 모델을 선택할지 결정해서 데이터를 어떤 형식(데이터 타입)으로 저장하고 어떤 제약조건을 적용할지 정한 다음 DBMS로 구현하는 것이다.
더 구체적으로 데이터 모델을 적용해서 설명하자면 개체-관계 모델을 이용하여 필요한 데이터들의 구조도를 그려보고, 관계 데이터베이스 모델에 따라 스키마를 결정하면 된다. 그리고 MySQL 같은 자신이 선택한 RDBMS 로 데이터베이스를 구축하면 된다.
개체-관계 모델이란
개체-관계 모델은 피터 첸(Peter Chen)이란 컴퓨터 박사가 1976년에 제안한 것으로, 개체-관계 다이어그램 (E-R 다이어그램)이라고도 한다. E-R 다이어그램은 데이터를 개념적으로 모델링한 결과물을 그림으로 표현하는 방법론으로 구성은 개체, 속성, 관계로 이루어져있다.
사각형, 마름모, 타원, 선 등을 이용하여 개체들의 일대일(1:1), 일대다(1:n), 다대다(n:m) 관계를 그림으로 표현한다.
사각형은 개체, 마름모는 개체 간의 관계, 타원은 개체나 관계의 속성을 나타낸다. 연결선(링크)는 각 요소를 연결하는 역할을 한다.

-
개체 (entity) : 독립된 하나의 개념적 존재로 RDBMS 에서는 하나의 테이블이라 생각하면 된다.

-
약한 개체(weak entity) : 두 개체가 있을 때 독자적으로 존재할 수 없고, 종속되는 개체를 약한 개체라고 한다. 예를들어 고객과 구매내역이라는 개체가 있으면 두 개체는 구매라는 관계로 이어지고, 구매내역은 고객이라는 개체가 없으면 의미가 없는 것이기 때문에 고객 개체에 종속된다. 여기서 고객을 오너개체, 구매내역을 약한 개체라고 부른다. 일반적으로 오너 개체와 약한 개체는 일대다(1:n)의 관계를 가진다. ( 오너 개체와 약한 개체가 맺는 관계는 이중 마름모로 표현한다. )

-
속성(attribute) : 속성은 개체가 가지고 있는 고유의 특성이다. 속성들이 모여 하나의 개체가 된다. RDBMS에서는 레코드 부분이라 생각하면 된다. 속성에도 종류가 있는데 아래의 그림과 같이 상품 번호처럼 밑줄 그어진 속성은 키 속성으로 개체의 각 인스턴스를 식별하는 역할을 한다. 할인율 같은 경우는 단일 속성으로 하나의 값을 가지는 일반적인 속성이다. 판매가격 같은 경우는 다른 속성의 값에 따라 값이 유도되어 결정된다고 하여 유도 속성이라 한다. 판매처의 경우 다중 값 속성이라 하여 값이 여러개가 존재할 수 있는 속성이다. 상품마다 판매처는 여러 곳일 수 있기 때문에 다중 값 속성이 되는 것이다.

-
관계(relationship) : 관계는 각각의 개체의 인스턴스들이 맺는 관계 유형에 따라 일대일(1:1), 일대다(1:n), 다대다(n:m) 으로 나누어진다.



이 외에도 E-R 다이어그램으로 표현 가능한 다양한 방법들이 있다. 자신의 목적에 맞게 사용하면 되겠다.
관계 데이터 모델
논리적 데이터 모델링에서 사용되는 관계 데이터 모델은 하나의 개체에 대한 데이터를 릴레이션(테이블) 하나에 담아 데이터베이스에 저장한다. 계층형, 네트워크형에 비해 개체 간 관계 표현이나 데이터 검색, 삽입, 삭제, 수정 등 데이터 연산에 더 유리하고 이해하기 쉬워 관계 데이터 모델을 가장 많이 사용한다. 논리적 데이터 모델링에서는 관계 데이터 모델에 맞게 릴레이션을 정의하고 각 속성에 맞는 스키마를 지정하는 작업을 하게 된다.
( ..E-R 다이어그램을 관계 데이터 모델로 옮기는 작업이다 생각하자. )
1. 관계 데이터 모델 용어 정리
-
속성 : 열 또는 어트리뷰트(attribute) 라고 부르며, 테이블에서 필드에 해당하는 부분이다. 속성은 서로 다른 이름을 붙여서 구분한다.
-
튜플 : 릴레이션(테이블)의 행을 튜플(tuple)이라고 한다. 개체의 인스턴스를 의미하며, 테이블에서 레코드에 해당하는 부분이다.
-
도메인 : 속성 하나가 가질 수 있는 값의 모음을 의미한다. RDBMS에서는 데이터 타입을 생각하면 된다.
-
널 값 : 널(null) 값은 특정 속성에 해당 값이 없는 경우를 나타낸다. ( 숫자 0 or 공백은 그 자체를 값으로 보기 때문에 null 이 아니다. )
-
차수 : 하나의 릴레이션(테이블)에서 속성의 전체 개수를 릴레이션의 차수(degree)라고 한다. 테이블에서 필드의 개수라고 생각하면 된다.
-
카디널리티 : 카디널리티(cardinality) 는 하나의 릴레이션에서 투플의 전체 개수를 의미한다. 즉 하나의 테이블의 레코드수( 데이터 수) 라고 보면 된다.
2. 릴레이션(테이블)의 특성
-
튜플의 유일성 : 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다는 뜻이다. 즉, 테이블에서 레코드가 중복되지 않는다는 의미인데 이러한 특성을 만족시키기 위해서 키(key) 라고 부르는 값의 중복이 불가능한 속성을 넣는다.
-
튜플의 무의미한 순서 : 릴레이션에서 튜플의 순서는 무의미하다는 뜻이다. RDBMS는 사람이 알아보기 쉽게 테이블 형태로 순차적으로 데이터를 담아 보여주지만 데이터들의 순서는 사실 상관없다. 데이터베이스는 위치가 아닌 내용으로 검색되기 때문이다.
-
속성의 무의미한 순서 : 릴레이션에서 속성의 순서 또한 의미가 없다는 뜻이다. 튜플과 마찬가지로 사람이 알아보기 쉽게 지정한 속성을 순서대로 보여주지만 데이터베이스에서는 상관없는 부분이다. 데이터베이스에서는 속성도 위치가 아닌 속성의 이름으로 속성을 구별하기 때문이다. 따라서 속성의 이름을 어떻게 짓느냐가 더 중요할 수 있다.
-
속성의 원자성 : 속성의 원자성이라는 특성은 속성의 값은 하나의 값(원자 값)만 가질 수 있다는 뜻이다.
3. 키(key)
키는 관계 데이터 모델에서 제약조건을 정의한다.
-
슈퍼키(super key) : 슈퍼키는 유일성을 만족하는 속성을 의미한다. 유일성이라는 것은 키 값이 유니크(unique)하다는 것이며 유일성은 키가 갖추어야 하는 기본 특성이다. 쉽게 설명하자면 키가 되는 속성의 값에는 중복이 없다는 것이다.
-
후보키(candidate key) : 후보키는 유일성과 최소성을 만족하는 속성이다. 최소성은 해당 키 속성이 없으면 튜플을 구별할 수 없는 꼭 필요한 속성을 의미한다. 여러 속성이 키로 지정될 수 있기 때문에 슈퍼키 중에서도 단독으로 튜플을 구별할 수 있는 속성들만 후보키가 될 수 있다.
-
기본키(primary key) : 기본키는 후보키 중에 기본적으로 사용할 키로 선택한 속성을 의미한다. 널(null) 값을 가질 수 있는 속성은 기본키로 부적합하고, 값이 변경될 가능성이 적은 후보키가 기본키로 적합하다. 예를들어 아이디값이나, 회원번호 같은 값들이 기본키로 적합하다 볼 수 있다.
-
대체키(alternate key) : 대체키는 기본키로 선택되지 못한 후보키들이다.
-
외래키(foreign key) : 외래키는 다른 릴레이션의 기본키를 참조하는 속성이다. 외래키는 관계 데이터 모델에서 관계를 이어주는 핵심이라고 볼 수 있는데, 다른 릴레이션의 기본키 값을 참조하여 릴레이션을 서로 이어준다. 쉽게 생각하면 테이블끼리 이어주는 값이라 보면 되고, 외래키는 다른말로 참조키라고 하는데 이름 그대로 참조하는 기본키의 값 내에서 값을 가져야한다. (참조할 수 없는 값은 가질 수 없다.) 외래키는 기본키를 참조하기 때문에 중복 값을 가질 수 있고, 기본키의 값 내에서 값을 가져야 한다고 했지만 예외로 널(null) 값은 가질 수도 있다.
4. 관계 데이터 모델의 제약 조건
관계 데이터 모델을 사용할 때 지켜야하는 조건을 관계 데이터 모델의 제약조건이라고 한다. 개체 무결성 제약조건과 참조 무결성 제약조건이 있는데 각각 기본키와 외래키에 관한 제약조건이다. 이 조건들은 데이터를 정확하고 유효하게 유지하기 위해 지켜야하는 조건이다.
-
개체 무결성 제약조건 : 기본키를 구성하는 모든 속성은 널(null) 값을 가질 수 없다.
-
참조 무결성 제약조건 : 외래키는 참조할 수 없는 값을 가질 수 없다. ( 다만, 널(null) 값은 예외로 참조 무결성 제약조건을 위반한 것으로 보지 않는다.)
'IT 정보 로그캣 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 데이터베이스 관리 시스템(DBMS)의 구성 (0) | 2019.06.17 |
|---|---|
| [데이터베이스] 관계형 데이터베이스(RDB)란 ? (0) | 2019.06.07 |
| [데이터 베이스] 데이터베이스란 ? (0) | 2019.06.07 |