Dart 란 Google이 개발한 오픈소스 프로그래밍 언어로 2011년에 처음 공개되어 어떤 플랫폼이든 빠른 앱 개발을 위해 클라이언트에 최적화된 언어이다. 많은 프로그래밍 언어들이 존재하는 이유는 제각각 추구하는 방향성이나 목표가 있기 때문인데 다트는 앱 프레임워크를 개발하기 위한 가장 생산적인 프로그래밍 언어를 제공하는 것이 목표이다. 다트가 Flutter 프레임워크 공식 개발언어인 이유도 여기에 있다. 다양하게 활용이 가능하지만 대부분 Flutter 를 개발하기 위해 사용한다.
Dart 언어 특징
다트는 주로 Java 와 많이 비교되고 비슷한 점이 많다.
정적 타입 언어지만 타입 추론도 지원
JIT(Just-In-Time)와 AOT(Ahead-Of-Time) 컴파일 모두 지원
멀티 플랫폼 지원 (웹, 모바일, 데스크톱)
정적 타입 언어란 정적 타입 언어란 변수의 타입이 컴파일 시점에 결정되는 언어로 한번 선언된 변수의 타입은 변경이 불가능하다.
JIT(Just-In-Time) 컴파일이란 실행 시점에 컴파일하는 것으로 핫 리로드(Hot Reload)가 가능하여 개발 환경에서 주로 사용된다. 대신 메모리 사용량이 많다.
AOT(Ahead-Of-Time) 컴파일이란 실행 전에 미리 컴파일하는 것으로 주로 프로덕션 환경에서 사용된다.
기본 문법
기본 구조
다트도 자바와 마찬가지로 void main() { ... } 처럼 최상위 레벨에 main 함수가 필요하다.
void main() {
print('Hello, World!');
}
변수 선언
다트도 기본적으로 다른 언어들과 비슷하게 타입 + 변수 명 = 변수 값 으로 구성된다. var 를 통해 타입 추론이 가능하며 명시적으로 타입을 선언해 줄 수도 있다. 타입뒤에 ? 을 붙여 Null Safety 을 적용할 수 있다. 만약 non-nullable 이면서 변수 초기화를 미루고 싶다면 타입 앞에 late 키워드를 붙여주면 된다. 상수는 final 과 const 사용이 가능한데 final 은 런타임 시점에 값이 결정되고 const 는 컴파일 시점에 값이 결정된다.
var name = 'Noah';
String? nullaleName = null;
late String lateName;
lateName = 'Noah';
타입
타입뿐만 아니라 전체적인 문법들이 거의 자바와 비슷하다. 타입은 int, double, num(int, 와 double 모두 포함), String, bool, List, Set, Map 등이 있다.
연산자
기본적인 연산자 모두 사용 가능하고 삼항 연산자도 사용이 가능하다. 타입의 경우 as 로 타입 캐스트를 하거나 is 로 타입 확인이 가능하다. 값비교는 == 로 모두 가능하지만 객체를 비교할 때는 identical(str1, str2) 형태로 사용해야 한다.
Mac은 기본적으로 Git 이 설치되어 있는데 버전도 낮고, 업그레이드 하려면 새로 다운로드를 받아야하는데 매번 이렇게 관리하는 것도 귀찮다. 그래서 맥북을 사용할 때 Homebrew 를 이용해서 대부분의 응용프로그램들을 관리하면 편하다. Git 도 마찬가지다
Homebrew 란? Homebrew 는 brew 라고 흔히 부르는데 MacOS 와 Linux 용 패키지 관리 매니저이다. brew 를 통해 패키지를 쉽게 설치하고 제거할 수 있다. 웬만한 프로그램은 다 있기 때문에 없는 것 빼고는 brew 를 통해 관리하는게 좋다. 프로그래밍을 할 때도 마찬가지지만 내가 통제할 수 있는 상태가 좋기 때문이다.
Git 설치
Homebrew 설치
Homebrew 가 설치되어 있지 않다면 먼저 설치하자. 아래 스크립트를 입력하면 자동으로 설치된다
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
$ brew list --cask
Homebrew 를 이용해 Git 설치
간단하다. 설치하기 전후로 git 버전을 확인해보면 엄청나게 차이가 많이나는 걸 확인할 수 있다.
$ brew install git
$ git --version
Git 기본 설정
Git 을 설치했으면 사용하기 전에 기본적으로 세팅해주자. 설정은 설정 명령어를 통해 설정 파일을 읽고 쓰는 방식으로 바꿀 수 있다. 설정의 우선순위는 저장소 > 사용자 설정 > 시스템 이다. 처음에는 사용자 이름과 이메일 주소 정도만 설정해주면 된다.
# 이름 설정
$ git config --global user.name "Noah"
# 이메일 설정
$ git config --global user.email "noah@example.com"
# 설정 확인
$ git config --list
도움말 보기
# Git config 명령 도움말
$ git help config
# Git 명령어 도움말
$ git help
개발 프로젝트를 할 때 Git 을 많이 사용한다. 협업을 위해서도 사용하고, 개인으로 프로젝트를 관리하기 위해서도 많이 사용한다. 보통은 Git 의 사용법만 적당히 익힌 뒤 사용하는 경우가 많아서 Git 의 기능을 제대로 사용하지 못하거나 충돌같은 문제가 생기면 제대로 대응하지 못하는 경우가 많다. 그렇기 때문에 Git 에 대해 알고 사용하자.
Git 이란
Git 은 컴퓨터 파일의 변경사항을 추적하고 협업을 하기 위한 분산 버전 관리 시스템이다. Git 은 2005년에 리눅스 토발즈와 리눅스 커널 개발자들이 함께 개발 하였다. 2002년에 오픈소스 프로젝트 리눅스 커널은 BitKeeper 라고 하는 상용 분산 버전 관리 시스템을 사용하였다. 그런데 2005년에 BitKeeper 가 유료화가 되면서 리눅스 커널과의 관계가 틀어지고, 리눅스 토발즈와 개발자들이BitKeeper 를 사용하면서 배운 점을 바탕으로 Git 을 만든 것이다.
Git 의 목표
지금도 그렇고 Git 이 추구하는 목표는 다음과 같다.
빠른 속도
단순한 구조
비선형적인 개발(수천 개의 동시 다발적인 브랜치)
완벽한 분산
리눅스 커널 같은 대형 프로젝트에도 속도나 데이터 크기 면에서 유용할 것
버전 관리란
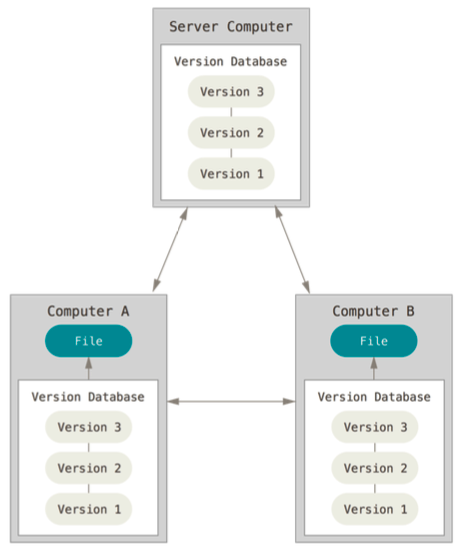
Git 에 대해 알기 위해서는 먼저 버전 관리에 대해 알아야 한다. 버전 관리 시스템(VCS, Version Control System)은 파일 변화를 시간에 따라 기록했다가 나중에 특정 시점의 버전을 다시 꺼내올 수 있는 시스템이다. 우리가 일상에서도 버전 관리 시스템을 쓰고 있는데 문서 되돌리기나, 포토샵에서 레이아웃 작업 이력 등도 모두 버전 관리 시스템이라 볼 수 있다. VCS 를 사용하면 각 파일을 이전 상태로 되돌릴 수 있고, 프로젝트를 통째로 이전 상태로 되돌릴 수도 있고, 시간에 따라 수정 내용을 비교해볼 수 있고, 누가 문제를 일으켰는지도 추적할 수 있고, 누가 언제 만들어낸 이슈인지도 알 수 있다. 또한 파일을 잃어버리거나 잘못 고쳤을 때도 쉽게 복구할 수 있다.
버전 관리 종류
로컬 버전 관리
VCS 는 로컬 버전 관리부터 시작된다. 로컬 버전 관리는 서버없이 내 컴퓨터에서 간단한 데이터베이스를 사용해 파일의 변경 정보를 관리하는 시스템이다. 버전을 관리하기 위해 디렉터리로 파일을 복사하는 방법을 사용할 수 있는데 이러면 디렉터리가 지워지거나, 실수로 파일을 수정하거나 잘못 복사할 수 있다. 이러한 이유로 프로그래머들에 의해 VCS 가 탄생하였다. 하지만 로컬 버전 관리는 말그대로 내 컴퓨터에서만 사용하기 위한 것으로 협업이 어려운 단점이 있다.
중앙집중식 버전 관리
중앙집중식 버전 관리(CVCS, Centrolized Version Control System) 는 파일을 관리하는 서버가 별도로 있고 클라이언트가 중앙 서버에서 파일을 받아서 사용(Checkout) 하는 시스템이다. 로컬 버전 관리로는 프로젝트 협업 등이 어렵기 때문에 만들어졌으며 Subversion(SVN) 같은 시스템이 대표적이다. 또한 관리자는 누가 무엇을 할지 관리할 수 있고, 모든 클라이언트의 로컬 데이터베이스를 관리할 필요 없이 VCS 하나를 관리하기 때문에 훨씬 쉽다. 하지만 CVCS 도 결점이 있는데 가장 대표적인 것이 중앙 서버가 다운되면 협업이 불가능하고, 백업할 방법도 없어진다. 그리고 중앙 데이터베이스가 있는 하드디스크에 문제가 생기면 프로젝트의 모든 히스토리를 잃는다.
분산 버전 관리 시스템
Git 과 같은 분산 버전 관리 시스템(DVCS, Distributed Version Control System)은 저장소를 전부 복제하는 방식의 시스템이다. 로컬 버전 관리나 중앙집중식 버전 관리의 결점들을 보완하여 클라이언트 중에서 아무거나 골라도 서버를 복원할 수 있고, 모든 Checkout 은 모든 데이터를 가진 진정한 백업이다. 대부분의 DVCS 환경에서는 리모트 저장소가 존재한다. 사람들은 동시에 다양한 그룹과 다양한 방법으로 협업할 수 있다. 계층 모델 같은 중앙집중식 시스템으로는 할 수 없는 워크플로를 다양하게 사용할 수 있다.
Git 의 특징
Subversion 이나 Perfoce 같은 것을 사용해봤다고 하면 개발한지 오래됐을 확률이 높다. Git 을 배우려면 SVN 등을 사용하던 경험을 버려야 한다고 하는데 작동 방식이 다르기 때문이다.
차이가 아닌 스냅샷을 저장한다
위에서 언급 했듯이 SVN 등과 Git 의 가장 큰 차이점은 데이터를 다루는 방법에 있다. SVN 등은 파일의 변화를 시간순으로 관리하면서 파일들의 집합을 관리한다. 즉 데이터 기반 관리 시스템인 것이다. 예를들어 1 + 2 + 3 을 쌓아 간다면 되돌아 가기 위해서는 -3, -2 로 역산해 나가야 한다. 대신 Git 은 시간순으로 프로젝트의 스냅샷을 저장한다. 파일이 달라지지 않았으면 Git 은 성능을 위해서 파일을 새로 저장하지 않는다. 단지 이전 상태의 파일에 대한 링크(레퍼런스 참고)만 저장한다. 그렇기 때문에 Git 은 한 달 전의 파일과 지금의 파일을 로컬에서 찾는다. 파일을 비교하기 위해 리모트에 있는 서버에 접근하고 나서 예전 버전을 가져올 필요가 없다. Git 은 데이터를 스냅샷의 스트림처럼 취급한다.
스탭샷(snapshot) 이란
컴퓨터 파일 시스템에서 스냅샷은 과거의 한 때 존재하고 유지시킨 컴퓨터 파일과 디렉터리의 모임이다. 스냅샷은 마치 사진을 찍듯이 특정 시점에 파일 시스템을 포착해 보관한다고 해서 붙여진 이름이다. 스냅샷은 원본 데이터를 그대로 복사해 다른 곳에 저장하는 백업과 달리 초기 생성 시 혹은 데이터의 변경이 있기 전까지는 스토리지의 공간을 차지하지 않는다.
거의 모든 명령을 로컬에서 실행한다
Git 은 거의 모든 명령이 로컬 파일과 데이터만 사용하기 때문에 네트워크에 있는 다른 컴퓨터는 필요 없다. 프로젝트의 모든 히스토리가 로컬 디스크에 있기 때문에 모든 명령이 순식간에 실행된다. “가장 빠른건 역시 localhost” 와 같은 이치다. 그래서 Git 에서 프로젝트의 히스토리를 조회할 때 서버가 필요없다.
Git 은 무결성을 보장한다
Git 은 데이터를 저장하기 전에 항상 체크섬을 구하고 그 체크섬으로 데이터를 관리한다. 체크섬은 Git 에서 사용하는 가장 기본적인(Atomic) 데이터 단위이자 Git 의 기본 철학이다. Git 은 SHA-1 해시를 사용하여 체크섬을 만든다. 만든 체크섬은 40자 길이의 16진수 문자열이다. 실제 사용할 때에는 줄여서 8글자만으로도 사용이 가능하다. 파일의 내용이나 디렉터리 구조를 이용하여 체크섬을 구한다. 실제로 Git 은 파일을 이름으로 저장하지 않고 해당 파일의 해시로 저장한다.
체크섬(checksum) 이란
체크섬은 자료의 무결성을 보호하는 단순한 방법이다. 데이터에 checksum 을 추가하여 연산을 통해 checksum 이 맞아 떨어지는지 확인해 봄으로써 데이터가 손상되지 않았다고 알 수 있다. 예를들면 위조 및 변조 방지를 위해 추가하는 주민등록번호 끝자리가 있다. 주민등록번호를 앞의 12자리 숫자에 각각 순서대로 2, 3, 4, 5, 6, 7, 8, 9, 2, 3, 4, 5 를 곱한 뒤 모두 더한다. 그리고 더한 값을 11로 나눠서 나온 나머지 값을 11에서 뺀 숫자와 주민등록번호 끝자리가 같으면 유효한 것이다.
Git 은 데이터가 추가 되기만 할 뿐이다
Git 으로 한 것이면 무엇이든 Git 데이터베이스에 데이터가 추가된다. 데이터를 되돌리거나 데이터를 삭제할 방법이 없다. 되돌리기나 삭제를 하면 되돌리거나 삭제 했다는 내역을 추가할 뿐이다.
세 가지 상태
Git 은 Committed, Modified, Staged 이렇게 세가지 상태로 관리한다.
Committed: 데이터가 로컬 데이터베이스에 안전하게 저장됐다는 것을 의미, Git 디렉터리 단계
Modified 는 수정한 파일을 아직 로컬 데이터베이스에 커밋하지 않은 것을 의미, 워킹 트리 단계
Staged: 현재 수정한 파일을 곧 커밋할 것이라고 표시한 상태를 의미, Staging Area 단계
Git 디렉터리는 Git 이 프로젝트의 메타데이터와 객체 데이터베이스를 저장하는 곳을 말한다. Git 디렉터리가 Git 의 핵심이다. 다른 컴퓨터에 있는 저장소를 Clone 할 때 Git 디렉토리가 만들어 진다.
워킹 트리는 프로젝트의 특정 버전을 Checkout 한 것이다. Git 디렉터리는 지금 작업하는 디스크에 있고 그 디렉터리안에 압축된 데이터베이스에서 파일을 가져와서 워킹트리를 만든다.
Staging Area 는 Git 디렉터리에 있다. 단순한 파일이고 곧 커밋할 파일에 대한 정보를 저장한다.
Git 의 프로세스는 다음과 같다.
워킹 트리에서 파일을 수정
Staging Area 에 있는 파일을 Stage 해서 커밋할 스냅샷을 생성
Staging Area 에 있는 파일들을 커밋해서 Git 디렉토리에 영구적인 스냅샷으로 저장
Git 디렉토리에 있는 파일들은 Committed 상태이다. 파일을 수정하고 Staging Area에 추가했다면 Staged 이다. 주로 스테이지에 올린다고 표현한다. 그리고 Checkout 하고 나서 수정했지만, 아직 Staging Area에 추가하지 않았으면 Modified이다.
코딩(혹은 프로그래밍) 공부를 하다 보면 정작 우리가 당연히 사용하는 컴퓨터에 대해서는 기본 지식인 양 넘어가는 것들이 많다. 그래서 코딩(혹은 프로그래밍) 공부를 시작하기 전에 상식으로 알아두면 좋을 것들을 간단히 정리해 보았다.
컴퓨터에 대해여
컴퓨터라(computer)는 이름은 계산하는 기계라는 뜻으로 "계산하다(compute)"라는 동사에서 유래되었다.(항상 이름의 뜻을 잘 알아두자!) 이렇듯 컴퓨터는 인간의 연산을 돕기 위해 컴퓨터가 발명된 것이다.
프로그래밍 언어
우리가 영어나 한글을 사용하듯이 컴퓨터는 0과 1로 이루어진 이진수를 언어로 사용한다. 이를 기계어라고 한다.
세상에 인간의 언어가 다양하듯이 프로그래밍 언어도 다양하고, 지금 이순간에도 새로운 프로그래밍 언어들이 만들어지고 있다. 대략적인 프로그래밍 언어의 발전 흐름을 살펴보면 다음과 같다.
1세대: 기계어
2세대: 어셈블리어
3세대: C, 포트란, 베이직, 코볼 등
4세대: 비주얼베이직, 델파이, 파워빌더 등
5세대: 자바, C++, C#, ASP, PHP 등
여기서 어셈블리어는 기계어를 그나마 사람이 사용할 수 있도록 0101001 같은 숫자를 기호화 한 언어라고 볼 수 있다.
3세대 언어들은 주로 절차 지향 중심의 언어들인데 이때부터 프로그래밍 언어가 컴퓨터보다 사람에게 더 친숙하게 만들어지기 시작한다.
그래서 기계어, 어셈블리어를 저급언어(low-level), 이후의 언어들을 고급 언어(high-level)라고 한다.
4세대 언어들은 주로 데이터를 처리하기 위한 데이터베이스 관련 프로그램을 개발할 수 있는 언어들이다.(대부분 5세대 언어들에 의해 대체되고 있다.)
5세대 언어들은 객체지향 언어가 많고 또한 네트워크 관련 기능이 강화된 언어들이 많다.
최근에 많이 쓰이는 언어들은 대부분 5세대 언어라고 생각하면 된다.
컴퓨터는 어떻게 우리가 작성한 코드를 알아들을까
컴퓨터의 언어는 0과 1로 이루어진 기계어인데 어떻게 우리가 작성한 프로그래밍 언어(코드)를 인지하는 걸까?
위에서 언급했듯이 3세대 언어부터는 사람에 친화적인 프로그래밍 언어이기 때문에 컴퓨터가 프로그래밍 언어를 이해하기 위해서는 별도의 번역기가 필요하다.
비유하자면 컴퓨터에게 어셈블리어까지는 사투리라고 한다면 3세대 언어부터는 아예 외국어가 되는 것이다.
그렇기 때문에 코드(프로그램)가 컴퓨터에서 실행되기 위해서는 컴퓨터가 인식할 수 있는 기계어로 번역되어야 한다.
사람에 의해 작성된 코드는 번역기를 거쳐 기계어로 번역되고, 컴퓨터는 기계어로 작성된 코드들을 실행하는 방식이다.
번역하는 방법에는 크게 컴파일, 인터프리트가 있다.
컴파일
컴파일(compile)은 코드를 컴파일러(compiler)라는 것을 사용해 기계어로 번역한 다음 번역된 파일을 생성해 컴퓨터에서 실행시키는 방법이다.
여기서 컴파일러는 프로그래머에 의해 만들어진 소프트웨어이다.
컴파일의 장점은 한번 작성된 코드가 번역되어 실행 파일이 생성되면 이후로는 다시 번역할 필요 없이 번역된 실행파일을 실행시키면 되기 때문에 시간상의 효율성이 뛰어나다.
단점으로는 특정 시스템에서 번역된 실행 파일은 다른 시스템에서는 실행되지 않는다. 예를 들어 윈도우에서 번역된 파일은 맥에서는 실행되지 않기 때문에 각각 시스템에 맞는 컴파일러를 별도로 만들어 줘야 한다. (윈도우용과 맥용 프로그램이 따로 있는 이유가 여기에 있다!)
인터프리트
인터프리트(interpret)는 인터프리터(interpreter)라는 것을 사용해 코드를 직접 한 줄씩 번역한 다음 바로 실행시키는 방법이다. 한 줄씩 번역하여 실행시키기 때문에 매번 버그가 발생할 때마다 전체를 컴파일하지 않아도 돼서 디버깅에 편리하다.
또한 인터프리터만 있으면 컴파일 방법처럼 시스템마다 별도의 컴파일러가 필요한 방식이 아니라서 이식성이 뛰어나다.
주로 스크립트 언어들이 인터프리트 방법을 사용한다.
하지만 한 줄씩 번역하고 실행시키다 보니 전체를 기계어로 번역해서 실행시키는 컴파일 방법보다는 상대적으로 시간 효율성이 떨어진다.
최근에는 컴파일과 인터프리트 방법을 모두 사용하는 하이브리드 방식을 사용하고 , 하드웨어 성능이 높아져서 예전처럼 컴파일 언어와 인터프리터 언어의 성능 차이를 사람이 체감할 정도로 크지 않다.
하이브리드 방식은 사람이 작성한 코드를 컴파일러를 사용해 중간 코드(바이트 코드)로 변환하고 이 중간 코드를 가상 머신을 통해 한 줄씩 기계어로 번역하여 즉시 실행시키는 방식이다.
운영체제
운영체제(OS, Operating System)는 사용자가 컴퓨터를 편리하게 사용할 수 있도록 하드웨어 자원을 관리해주는 소프트웨어이다. 초기에는 컴퓨터 제작 회사별로 각자의 운영체제를 만들어 제공하였지만, 퍼스널 컴퓨터(PC)가 등장하고 나서부터는 일관된 형태의 운영체제가 사용되고 있다.
운영체제의 종류
DOS(Disk Operating System)
일명 도스로 불리며 퍼스널 컴퓨터가 처음 개발되었을 때 사용했던 운영체제이다. DOS는 명령어를 직접 입력하여 운영체제를 사용하는 CUI(Command-line User Interface) 형태의 운영체제이다. 맥에서 터미널이나 윈도우에서 콘솔 창이 이에 해당한다.
Windows 계열 운영체제
우리가 모두 그 Windows 다. Windows는 마우스로 편리하게 사용할 수 있는 GUI(Graphical User Interface) 방식의 운영체제로 1985년 마이크로소프트 사는 Windows 1.0 운영체제를 처음 발표하였다.
이후 Windows 1.0 ~ 3.0, Windows 95, Windows NT(New Technology), Windows 2000, Windows XP, Windows Vista, Windows 7 ~ 10 등이 계속해서 개발되었다.
Mac 운영체제
1984년 미국의 애플에서 매킨토시 계열의 퍼스널 컴퓨터나 워크스테이션에서 사용할 수 있는 Mac 운영체제를 개발하였다. Mac 운영체제는 마우스를 사용하는 최초의 GUI 형태의 운영체제이다.
유닉스(Unix) 계열 운영체제
1969년 미국의 AT&T사의 벨 연구소에서 개발된 운영체제로 주로 중대형 컴퓨터의 운영체제로 사용되었다. 1974년 데니스 매 캘리 스테어 리치(이름도 어렵다...)가 유닉스를 C 언어로 다시 개발하였고, 서로 다른 기종의 컴퓨터에도 유닉스가 쉽게 이식되어 사용될 수 있게 되었다. 그 이후 유닉스는 발전을 거듭하여 상용 운영체제인 솔라리스와 FreeBSD 유닉스를 탄생시켰다.
리눅스(Linux) 운영체제
1991년 핀란드 헬싱키 대학교의 학생인 리누스 토발즈에 의해 만들어진 운영체제로 유닉스를 PC에서 사용할 수 있게 만든 운영체제이다.
리눅스는 누구나 변환하여 사용할 수 있는 오픈소스이며, 개인용 컴퓨터 운영체제 또는 서버용 운영체제로도 많이 사용된다.
리눅스는 처음부터 소스코드를 공개하여 많은 사용자들로부터 유틸리티 소프트웨어가 만들어졌고, 배포판으로는 레드햇(Red Hat), 데비안(Debian) 등이 제공되고 있다.
스마트폰 운영체제
스마트폰에서 사용되는 운영체제로는 구글의 안드로이드, 애플의 iOS 등이 대표적이고 그 외 심비안, 블랙베리, 윈도우폰 7, 삼성의 바다 등이 있다.
데이터의 표현
이진수의 표현
컴퓨터는 0과 1로 구성된 이진수를 바탕으로 모든 데이터를 표현한다.
하나의 0이나 1을 비트(bit)라고 한다. 이진수를 사용하여 상태를 표현하면 두 가지 상태만 나타낼 수 있으므로 여러 개의 비트를 모아 하나의 상태를 표현한다.
컴퓨터에 저장할 수 있는 정보의 규모를 나타내는 단위
문자의 표현
컴퓨터에서 사용하는 문자에는 영문자, 한글, 숫자, 특수 기호 문자 등이 있다.
초기의 컴퓨터에서는 컴퓨터마다 서로 다른 문자 코드 체계를 사용하여 프로그램의 호환성이 문제가 되었다. 이러한 호환성을 해결하기 위해 표준화된 코드체계가 필요했고, 그렇게 만들어진 대표적인 코드 체계로 아스키(ASCII) 코드와 유니코드(Unicode)가 있다.
아스키코드(ASCII, Amercian Standard Code for Information Interchange)
아스키코드는 영문 알파뱃을 사용하는 대표적인 표준 코드체계로 1967년에 표준으로 제정되었다.
아스키 코드는 7비트를 사용하여 표현하는 코드 체계로 33개의 제어 문자들과 공백을 포함하는 95개의 출력 가능한 문자로 구성되어 있다.
출력 가능한 문자들은 52개의 영문 알파벳 대소문자와 10개의 숫자, 32개의 특수 문자, 하나의 공백 문자로 이루어져 있다.
정규 표현식 리터럴은 스크립트가 불러와질 때 컴파일 된다. 그래서 정규 표현식이 상수일 때 성능이 더 좋다.
RegExp 객체의 생성자 함수를 호출하는 방법
const regex = new RegExp("no+ah");
생성자 함수를 사용하면 정규 표현식이 실행 시점에 컴파일 된다.
정규 표현식의 패턴이 변경될 수 있는 경우나 사용자 입력과 같이 다른 출처로 부터 패턴을 가져와야 하는 경우 생성자 함수를 사용한다.
자바스크립트에서 정규식 표현 패턴
자바스크립트에서 정규 표현식 패턴은 단순히 문자로 구성할 수도 있고 메타문자를 사용할 수도 있다.
단순 문자 패턴
단순히 문자로 구성하는 경우 /noah/ 로 작성하여 사용하면 문자열에서 noah 라는 부분의 문자열을 찾을 수 있다.
예를들어 "Who is noah?" 에서는 noah와 대응될 것이고, "Do you know Annah?" 에서 no 와 ah 가 부분적으로 포함되지만 noah의 형태가 정확히 포함되지 않기 때문에 대응되지 않는다.
메타문자를 사용한 패턴
자바스크립트에서 사용할 수 있는 메타문자들은 다음과 같다.
\ : 백슬래쉬는 문자 앞에 붙어 사용되는 경우 해당 문자는 글자 그대로 문자가 아닌 메타문자를 나타냄을 의미한다. 예를들어 정규 표현식에서 d 를 입력하면 소문자 그대로 d를 의미하지만 백슬래쉬를 앞에 붙여 \d 를 입력하면 숫자를 의미하는 메타문자가 된다. 반대로 백슬래쉬가 특수문자 앞에 붙어 사용되는 경우 특수 문자각 메타문자가 아닌 문자 그대로의 특수문자를 의미한다. 예를들어 /m*/ 은 m이 0번 이상 반복됨을 나타내는 정규 표현식이지만 /m\*/ 으로 작성하면 m* 문자를 의미한다.
^ : 입력의 시작 부분을 의미한다. /^m/ 이라고 입력하면 A로 시작하는 문자열에만 대응한다.
$ : 입력의 끝 부분을 의미한다. /m$/ 이라고 입력하면 m으로 끝나는 문자열에만 대응한다.
* : 앞에 입력된 문자가 0번 이상 반복됨을 의미한다. {0,} 으로도 표현할 수 있다. /no*ah/ 라고 작성하면 "nah" 또는 "nooooooah" 등과 대응 된다.
+ : 앞에 입력된 문자가 1번 이상 반복됨을 의미한다. {1,} 으로도 표현할 수 있다. /no+ah/ 라고 작성하면 "noah" 또는 "noooah" 등과 대응 된다.
? : 앞에 입력된 문자가 0번 또는 1번 나타남을 의미한다. {0,1} 으로도 표현할 수 있다. /no?ah/ 라고 작성하면 "nah" 또는 "noah" 만 대응 된다.
. : 개행 문자를 제외한 임의의 문자 하나를 의미한다. /.o/ 라고 작성하면 "This is a blog of noah" 에서 lo 와 no 와 대응 된다.
(text) : 여기서 괄호를 포획 괄호라고 부르며 문자열을 묶어서 대응시켜 준다. 예를들어 tistory noah 문자열에서 각각 tistory와 noah로 묶어서 나타내고 싶을 때 각 문자열을 /(\w+)\s(\w+)/ 와 같은 형식으로 대응 시켜 표현할 수 있다.
(?:text) : 비포획 괄호라고 하여 정규 표현식 연산자가 text 문자열 전체에 동작할 수 있게 하고 싶을 때 사용할 수 있다. 예를들어 /abc+/ 는 c가 반복되는 것을 나타냄으로 "abcabcabc" 에서 처음 abc에만 대응되지만 /(?:abc)+/ 라고 하면 abc 전체가 반복되는 것을 대응할 수 있다.
prefix(?=suffix) : suffix 가 뒤따라오는 prefix만 대응된다. 예를들어 noah(?=log|blog) 라고하면 noahlog 또는 noahblog 에 대응된다.
prefix(?!suffix) : suffix 가 뒤따라오지 않는 prefix 에만 대응된다. 예를들어 /\d+(?!\.)/ 은 소수점이 뒤따라오지 않는 숫자에만 대응되어 3.1417 이면 1417에만 대응된다.
x|y : x 또는 y 에 대응된다.
{n} : 앞 문자가 n번 나타날 경우 대응된다. (n은 양의 정수) /p{2}/ 이면 "apple" 에서 'pp'에 대응된다.
{n,m} : 앞 문자가 n번 이상 m번 이하일 경우에 대응된다. /o{2,3}/ 이면 "noooah" 에서 'ooo' 에 대응된다.
[text] : 문자셋(Character set)을 의미한다. [ ] 안에서는 점(.) 과 별표(*)도 단순 문자로 인식된다. 하이픈을 사용하면 범위를 지정할 수 있다. [ ] 안에서는 ^ 는 not 을 \b 는 백스페이스를 의미한다. 예를들어 /[a-z]/ 는 알파벳 전체 범위를 의미한다.
\b : 단어의 경계(시작이나 끝)을 의미한다.
\B : 단어의 경계가 아닌 곳(단어의 시작과 끝 사이)을 의미한다.
\cX : 문자열 내부의 제어 문자에 대응된다. X는 A ~ Z 까지의 문자 중 하나다.
\d : 숫자에 대응된다 [0-9]와 동일하다.
\D : 숫자가 아닌 문자에 대응된다. [^0-9]와 동일하다.
\f : 폼피드 문자에 대응된다.
\n : 줄 바꿈 문자에 대응된다.
\r : 캐리지 리턴 문자에 대응된다.
\s : 스페이스, 탭, 폼피드, 줄 바꿈 문자 등을 포함한 하나의 공백 문자에 대응 된다.
\S : 공백 문자가 아닌 하나의 문자에 대응된다.
\t : 탭 문자에 대응된다.
\v : 수직 탭 문자에 대응된다.
\w : 밑줄를 포함한 영숫자에 대응된다. [A-Za-z0-9_] 으로도 표현할 수 있다.
\W : 단어 문자가 아닌 문자에 대응된다. [^A-Za-z0-9_] 으로도 표현할 수 있다.
\숫자 : 정규 표현식 내부의 숫자 번째 괄호에서 대응된 부분에 대한 역참조
\0 : null 문자에 대응한다.
정규 표현식 플래그를 통한 검색
정규 표현식은 정규 표현식 패턴 구분자가 끝나는 곳에서 플래그를 추가해 줄 수 있다. 플래그는 각각 사용될 수도 있고 함께 사용될 수도 있다. 플래그 끼리의 순서에는 구분이 없다. 주로 많이 사용 되는 플래그는 다음과 같다.
이 때 특수 문자가 반드시 들어가야 한다든지 특정 특수 문자는 입력이 불가능 하다든지와 같이 유효성 검사를 할 때 정규 표현식이 요긴하게 사용된다.
또한 텍스트에서 특정 정보나 패턴을 찾을 때 혹은 단어나 데이터 등을 변환할 때에도 정규 표현식을 사용할 수 있다.
간혹 정규 표현식을 사용하면 알고리즘 문제 등도 쉽게 해결되는 경우도 있다.
정규 표현식도 결국 개발자(정규표현식은 개발자 이외에도 자료를 다루는 사람 등도 해당된다.)의 생산성이나 유지보수에 있어서 좋기 때문에 사용한다고 보면 된다 :)
정규 표현식(Regular expression) 이란
정규 표현식은 정규식, Regex 으로도 많이 부르는데 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다.
한글로 표현하면 뜻이 더 어렵게 느껴지는데 영어 그대로 보자면 규칙적인 것, 일종의 패턴을 표현하는 언어라고 보면 된다.
정규 표현식은 대부분의 프로그래밍 언어나 텍스트 편집기(Intellj, visual studio code ...), OS(Unix/Linux, Mac, Windows) 에서 사용할 수 있다.
정규 표현식의 역사
정규 표현식은 1956년 스티븐 클레이니가 정규 집합(regular set)이라는 자신의 수학적 개념을 이용하여 정규 언어를 기술한 것을 기원으로 보고 있다. 여러 형태의 정규 표현식이 유닉스 프로그램에 사용되었고, 이후에 정규 표현식이 POSIX에 표준으로 인정 되었다.
POSIX의 정규 표현식도 다시 Basic 과 Extended 로 나뉘어 진다.
POSIX(Portable Operating System Interface X, x는 유닉스 호환 운영체제에 보통 x가 붙는 것에서 유래) 란
POSIX는 이식 가능 운영체제 인터페이스라는 뜻으로 서로 다른 UNIX OS의 공통 API를 정리하여 이식성 높은 유닉스 응용 프로그램을 개발하기 위한 목적으로 IEEE가 책정한 애플리케이션 인터페이스 규격이다. 즉, UNIX OS 간에 호환이 가능하도록 기준을 마련한 것으로 이해하면 된다.
1980년대에 POSIX의 정규 표현식을 확장한 Perl의 정규 표현식이 등장했으며, 이 또한 PCRE (Perl Compatible Regular Expressions)로 정리되며 많은 프로그래밍 언어에서 사용된다.
정규 표현식은 하나의 갈래로 이어져 확장되는게 아니라 기본적인 체계는 비슷하면서도 사소하게 다른 형태로 나뉘어져 있다.
그래서 정규 표현식은 프로그래밍 언어마다 문법이 조금씩 다르다.
하지만 또 그렇게 큰 차이는 없어서 언어 별로 정규 표현식을 사용하는데 어려움은 없지만 다량의 텍스트를 다룰 때는 실수를 할 수 있는 확률이 높아 주의할 필요가 있다. 때문에 자신이 사용하는 언어의 정규 표현식을 확인은 하고 사용하는게 좋다.
정규 표현식 문법
패턴 구분자
정규 표현식의 패턴이 달라질 경우 패턴을 구분하는 문자인데 보통은 슬래쉬(/)로 정규 표현식을 감싸준다.
"보통은" 이라고 말한 이유는 꼭 슬래쉬(/)가 아니어도 되기 때문이다.
예를들어 아래 처럼 해쉬(#) 나 (%) 등 특수문자 중에 공백이 아닌 문자나 역슬래쉬(\)를 제외하고는 아무거나 사용이 가능하다.
/^[0-9]*$/
#^[0-9]*s#
%^[0-9]*s%
메타 문자
정규 표현식에서 일정한 의미를 가지고 사용되는 특수문자를 메타 문자라고 한다.
^ : 문자열의 시작
$ : 문자열의 종료
. : 임의의 한 문자
| : or 을 의미
[] : 문자 클래스. 문자 클래스 안에서 ^ 는 not 을 의미하고 - 는 범위를 의미함
? : ?의 앞 문자가 없거나 하나 있음
+ : +의 앞 문자가 하나 이상 있음
* : *의 앞 문자가 0개 이상 있음
{n} : {n}의 앞 문자가 정확히 n개 있음
{n,} : {n}의 앞 문자가 n 번 이상 있음
{n,m} : 앞 문자가 n개 이상 m개 이하로 있음
() : 연산자의 범위와 우선권을 정의할 수 있음
\s : 공백 문자
\b : 문자와 공백 사이를 의미
\d : 숫자 [0-9]와 동일
\t : 탭문자
\w : 밑줄(_)을 포함한 영숫자 문자로 [A-Za-z0-9_]와 동일
* 문자 이스케이프는 대문자로 적으면 반대를 의미한다.
패턴 변경자
패턴 구분자가 끝나면 그 뒤에 쓰는 것으로, 패턴에 일괄적으로 변경을 가할 때 사용한다.
g: global을 의미하며 문자열 내의 모든 패턴을 찾음 (^ 를 문서의 처음에 $ 를 문서의 끝에 매치되게 변경)
i : ignore case를 의미하며 대소문자를 구별하지 않음
m : Multi line을 의미하며 문자열에 줄바꿈이 있더라도 패턴을 찾음
s : 문자열에 개행 문자(\n)도 포함하여 패턴을 찾음
x : 공백 문자를 무시함
자주 사용되는 정규 표현식
숫자 : ^[0-9]*$
영문자: ^[a-zA-Z]*$
유니코드 한글: ^[가-힣]*$
언급했듯이 프로그래밍 언어 마다 조금씩 지원하는 정규 표현식 문법이 다르기 때문에 이정도의 기본 정도만 익혀두고 자기가 사용하는 언어의 정규 표현식을 찾아 따로 확인을 해야한다.
어차피 대부분 정규 표현식을 자주 까먹기 때문에 보통은 정규 표현식을 작성할 때 마다 다시 확인하는 경우가 많다. (나만 그런가?)
하지만 정규 표현식을 잘 익혀두면 유용하게 사용하는 경우가 많아서 한 번쯤은 공부하고 정리하는게 필요한 부분이다.
Node.js 로 프로젝트를 진행하다 보면 필수적으로 npm 사용하게 된다. 당연히 쓰다보니 당연해진 NPM이 뭔지는 알고 사용하자.
npm 이란
npm 이란 노드 패키지 매니저 (Node Package Manager)를 의미한다. npm은 자바스크립트 런타임 환경인 Node.js 의 기본 패키지 관리자 역할을 한다. 그래서 npm을 통해 패키지 (package) 또는 모듈 (module) 이라고 불리는 자바스크립트 소프트웨어를 자신의 프로젝트에 설치할 수 있다. 또한 npm을 통해 자신의 프로젝트에서 사용 중인 패키지들의 버전 업데이트도 관리할 수 있다.
npm의 구성
npm은 다음과 같이 3가지로 구성되어 있다.
npm 웹사이트
CLI (Command Line Interface)
저장소
npm 웹사이트
npm 웹사이트 는 패키지를 찾을 수 있다. 보통 구글에서 npm <패키지 이름> 을 검색하면 npm에서 해당 패키지의 저장소 페이지가 나온다.
CLI
npm은 터미널에서 CLI를 통해 작동시킬 수 있다.
예를들어 npm init -y 을 통해 package.json 파일을 만들어 프로젝트를 시작할 수 있고, npm install <패키지 명> 으로 해당 프로젝트에서 패키지를 설치할 수도 있다.
저장소
npm에는 패키지들을 모아놓은 공개 저장소가 존재한다. 계정을 업그레이드 시키면 비공개 저장소도 사용이 가능하다.
개발을 하다보면 REST API 를 많이 사용하게 되는데 정말 내가 진짜 REST API 를 사용하고 있는가 다시한번 생각해 볼 수 있는 좋은 자료가 있어서 참고하여 나름대로 정리해 보았다.
REST API (Representational State Transfer Application Programming Interface) 란
REST API 는 REST 아키텍쳐를 스타일을 따르는 API로 여기서 REST 란 분산 하이퍼미디어 시스템을 위한 아키텍쳐를 의미한다.
REST는 HTTP 창시자 중 한 명인 로이 필딩(Roy Fielding)의 박사학위 논문에서 최초로 소개된 개념으로 웹과의 호환성을 유지하면서 웹의 장점을 최대한 활용할 수 있는 아키텍쳐를 제시하기 위해 만들어 졌다.
(.. 잘 설계된 웹을 잘 사용하라고 아키텍쳐까지 발표했지만 여전히 어렵다.)
REST의 특징
그렇다면 REST는 어떤 아키텍쳐인가 알기 위해 특징을 살펴보면 다음과 같다.
Client-Server 구조
REST 서버가 API 를 제공하고, 클라이언트는 사용자 인증이나 컨텍스트(세션, 로그인 정보) 등을 직접 관리하고 책임 지는 구조이다.
Stateless (무상태성)
REST 는 Stateless 즉, 상태를 유지하지 않는 특징을 가지는데 상태를 유지하지 않는 다는 것은 HTTP 세션이나 쿠키 같은 상태 정보를 저장하지 않는 다는 것을 의미한다. REST 서버는 단지 클라이언트의 요청만 처리할 뿐이라 구현이 단순하다.
Cache (캐시)
REST는 HTTP라는 기존 웹 표준을 그대로 사용하기 때문에 HTTP의 캐시 기능을 사용할 수 있다. 애초에 REST가 웹과의 호환성을 고려하여 만들어 졌기 때문에 당연하다고도 볼 수 있다. 예를들어 Last-Modified 태그 등을 사용하여 컨텐츠에 변화가 없으면 클라이언트가 캐싱해놓은 값을 사용하여 서버에 불필요한 트랜젝션 을 발생하지시키지 않아 서버 자원을 효율적으로 사용할 수 있다.
Layered System (계층형 시스템)
REST 서버는 다중 계층으로 구성이 가능하여 HTTP 프로토콜 기반의 로드 밸런서나 SSL (암호화 계층)을 추가할 수 있다.
Uniform Interface (일관성 있는 인터페이스)
REST 는 URI 로 지정한 리소스에 대해 일관성 있는 인터페이스를 제공함으로써 클라이언트와 서버가 독립적인 진화가 가능하다.
진화라는 말이 어색하지만 독립적인 진화라는 말은 쉽게 설명하면 서버가 변경되어도 클라이언트가 따로 업데이트를 할 필요가 없다는 것이다. 예를들어 웹 표준을 잘 지키고 있는 웹 브라우저를 생각하면 된다. 개발자가 서버를 아무리 변경해도 해당 서버에 접속하는 클라이언트는 웹 브라우저를 업데이트할 필요가 없다.
Uniform Interface 의 원칙
로이 필딩은 현재 REST API 라고 주장하는 API 들이 진짜 REST 가 아니며 제대로 REST 의 원칙을 지키거나 HTTP API 와 같은 이름을 사용하라고 말한다.
( .. 자신이 만든 REST 의 원칙을 제대로 안지키면서 REST 라고 떠들고 다니니 답답한 모양이다. )
여기서 로이 필딩이 말하는 REST의 원칙은 Uniform Interface 의 원칙을 의미한다.
Identification of resource (자원의 식별)
말 그대로 자원을 식별할 수 있어야 한다는 원칙인데, 쉽게 생각하면 REST를 구현하기 위해 설계하는 URI 를 생각하면 된다. URI를 통해 자원을 표현하는 것이다.
(.. 많은 개발자들이 URI 를 간단하고 직관적으로 설계하기 위해 고민하는 부분이다. )
Manipulation of resources through representations (표현을 통한 자원의 조작)
클라이언트가 어떤 자원을 가르키는 표현과 특정 메타데이터만 가지고 있다면 서버 상의 해당 자원을 변경 또는 삭제 할 수 있어야 한다는 원칙이다. REST API 를 설계할 때 자원에 대한 표현을 HTTP 메서드인GET,POST,PUT,DELETE 등을 사용하는 부분이라 생각하면 되겠다.
Self-descriptive messages (자기 서술적 메시지)
각 메시지에는 메시지를 어떻게 처리해야 하는지에 대한 충분한 정보를 포함해야한다는 원칙이다.
Uniform Interface 에서 주로 지켜지지 않는 원칙 중 하나로 URI 와 메서드, 메시지 포맷 등으로 REST API 를 쉽게 이해할 수 있어야 한다는 말이다.
예를 들면 HTTP 헤더의 미디어 타입의 정의를 들 수 있다. 미디어 타입의 정의 만으로 해당 메시지를 어떻게 처리해야 하는지 클라이언트가 알 수 있어야 한다.
Hypermedia As The Engine Of Application State(HATEOAS, 애플리케이션 상태에 대한 엔진으로서의 하이퍼미디어 )
이름만 들어도 거창한데 마찬가지로 Uniform Interface 에서 주로 지켜지지 않는 원칙 중 하나로 애플리케이션의 상태가 하이퍼미디어(하이퍼링크)를 통해 제공되어야 한다는 원칙이다.
예를 들어 링크 형태를 이용하면 서버에서 자원에 대한 URI를 변경하더라도 클라이언트에서는 코드 수정이 불필요 하다. 클라이언트는 서버에서 주어진 링크만 따라가면 되므로 서버는 링크를 동적으로 변경할 수 있기 때문이다.
REST API 를 사용해야 할까?
결국 REST API 에서 가장 많이 하는 고민.
개인적인 생각은 "사용하면 좋다" 이다.
다만 REST API 를 제대로 사용하는 것에 대해서는 고민을 해봐야할 것 같다.
REST API의 창시자인 로이 필딩은 다음과 같이 말했다고 한다.
"시스템 전체를 통제할 수 있다고 생각하거나, 진화에 관심이 없다면, REST에 대해 따지느라 시간을 낭비하지 마라."
(.. 명언이다. 실제로 REST 따지느라 시간 낭비를 많이 했었다 )
보통은 URI 나 HTTP 메서드 만 열심히 고민하고 REST API 를 사용했다고 한다.
많은 인싸(?) IT 회사들도 REST API 라고 언급 하지만 위의 원칙들을 다 지키지 않는 경우가 많다.
(.. 시스템 전체를 통제할 수 있는 범위 내에서 적당하게 사용하는 것 같다.)
마이크로소프트는 REST API 가이드라인까지 발표했지만 로이 필딩이 친히 그건 REST API 가 아니라고 까주었다. 중요한건 REST API 는 웹을 잘 활용할 수 있는 아키텍쳐이고, REST 의 원칙들을 자기 상황에 맞게 맞춰 사용하면 된다.
(.. 다만 REST 원칙을 모두 준수하지 않고 REST API 라고 명칭하는건 양심의 문제랄까)
REST API 설계 가이드
REST API 의 특징들은 웹에서 사용하는 기존 인프라를 그대로 활용하는 것들이라 대부분 자동적(?)으로 지켜진다. 그렇기 때문에 특별히 신경써야할 Uniform Interface 의 원칙에 따라 REST API 설계를 간단하게 해보자면 다음과 같다.
1. URI 는 자원을 표현
간단하면서도 직관적으로 만들고 명사를 사용한다.
예) /{colletions}/{id} -> /users/1
2. 표현을 통한 자원의 조작
HTTP 메서드 GET, POST, PUT, DELETE 등을 사용
예) get /users/1 : 아이디가 1 인 유저의 정보를 가져온다.
post /users/2: 아이디가 2인 유저를 추가 한다.
3. 자기 서술적 메시지
미디어 타입을 정의하고나서 IANA에 직접 등록하는 방법과 HTTP Link 헤더에 profile relation 으로 API 문서를 링크하는 방법이 있다.
예) Link : <https://example.com/docs/users>: rel="profile"
네트워크 기술이란 서버와 클라이언트의 정보가 오고 가는 다리 역할을 하는 기술의 총칭을 의미한다.
네트워크라는 말은 연결되어 있다라는 뜻으로 컴퓨터 네트워크는 데이터를 케이블에 실어 나르는 것을 의미한다.
(무선 LAN은 전파로 데이터를 실어 나른다.)
LAN (Local Area Network)
LAN 이란 기업이나 조직 등 비교적 좁은 범위 안에 존재하는 컴퓨터 네트워크를 의미한다.
LAN은 LAN 케이블을 이용하여 데이터를 전송하는 유선 LAN과 전파를 이용하여 데이터를 전송하는 무선 LAN으로 구분한다.
LAN 케이블 이란 LAN 케이블은 LAN을 연결 하기 위한 케이블
LAN 스위치 란 LAN 스위치는 LAN을 구성하기 위한 네트워크 기기
네트워크 작동 원리
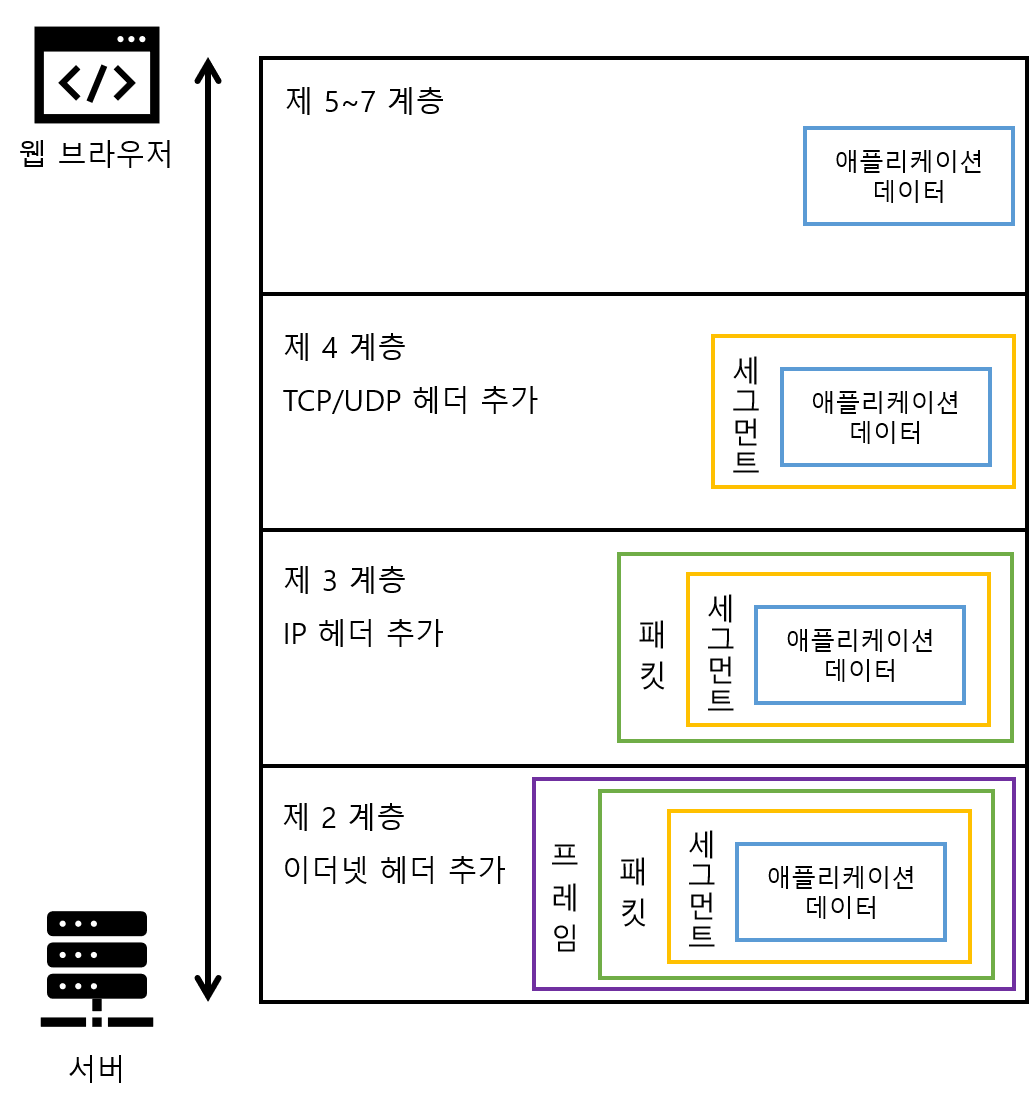
네트워크는 OSI 참조 모델을 바탕으로 작동한다. OSI 참조 모델은 국제표준화기구(ISO)가 컴퓨터 통신 기능을 계층 구조로 나눠서 정리한 모델로 일종의 통신 규칙 모음이라 생각하면 된다.
보통 OSI 7계층이라고 하는데 하위 계층(물리 계층) 부터 상위 계층(전송 계층)으로 구성된다.
OSI 7계층
제 1계층(물리 계층) : 네트워크 케이블의 재질이나 커넥터의 형식, 핀의 나열 방법 등 물리적인 요소를 모두 규정한다.
제 2계층(데이터 링크 계층) : 직접 연결된 기기 사이에 논리적인 전송로(데이터 링크)를 확립하는 방법을 규정한다.
제 3계층(네트워크 계층) : 동일 또는 다른 네트워크의 기기와 연결하기 위한 주소와 경로의 선택 방법을 규정한다.
제 4계층(전송 계층) : 데이터를 통신할 상대에게 확실하게 전달하는 방법을 규정한다.
제 5계층(세션 계층) : 데이터를 흘려보내는 논리적인 통신로(커넥션)의 확립과 연결 끊기에 대해 규정한다.
제 6계층(표현 계층) : 애플리케이션 데이터를 통신에 적합한 형태로 변환하는 방법을 규정한다.
제 7계층(응용 계층) : 애플리케이션 별로 서비스를 제공하는 방법을 규정한다.
OSI 참조 모델
프로토콜
응용 계층 (제 7계층)
애플리케이션 프로토콜 (HTTP 등)
표현 계층 (제 6계층)
애플리케이션 프로토콜 (HTTP 등)
세션 계층 (제 5계층)
애플리케이션 프로토콜 (HTTP 등)
전송 계층 (제 4 계층)
TCP / UDP
네트워크 계층 (제 3 계층)
IP / ICMP / ARP
데이터링크 계층 (제 2계층)
이더넷
물리 계층 (제 1계층)
이더넷
<OSI 참조 모델과 프로토콜 >
프로토콜
프로토콜이란 네트워크 통신을 위한 통신규칙을 의미한다.
프로토콜의 역할은 데이터의 캡슐화와 캡슐 해제화를 하는 것이다. 네트워크 통신에서 OSI 참조 모델의 계층을 넘어설 때마다 데이터를 캡슐에 넣거나 꺼낸다.
프로토콜 캡슐화 / 캡슐 해제화
이더넷
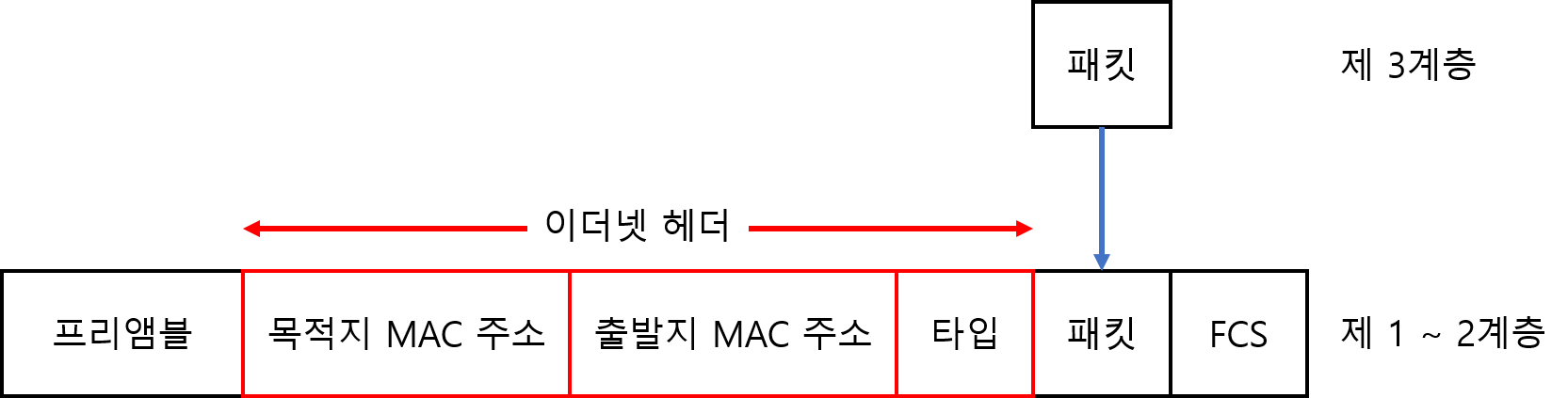
이더넷은 OSI 제 1계층과 제 2 계층의 기술 규격이다. 유선 네트워크의 경우 거의 대부분이 이더넷을 사용한다.
이더넷은 네트워크 계층으로부터 받은 데이터(패킷)에 프레임의 처음을 나타내는 프리앰블(preamble)과 목적지(수신자)와 출발지(송신자)를 나타내는 헤더, 비트 오류체크에 사용하는 FCS(Frame Check Sequence)를 추가하여 프레임을 생성한다. 이더넷은 MAC 주소라는 48비트로 된 식별자를 사용하여 컴퓨터를 식별한다.
프레임 구조
MAC 주소
MAC 주소란 데이터링크 계층(제 2계층)에서 통신을 위해 사용되는 48비트로 된 식별자이다.
MAC 주소는 8비트 마다 하이픈( - ) 이나 콜론 ( : ) 으로 구분하여 16진수로 표기한다.
상위 24비트는 전기 및 전자관계 기술자 단체인 미국전기전자학회(IEEE)가 기기의 제조업체 별로 할당한 제조업체 코드(OUI, Organizationally Unique Identifier) 라고 하는데 해당 코드로 제조업체를 알 수 있다.
하위 24비트는 제조업체가 기기 별로 고유한 값을 할당한 코드이다.
NIC 에 할당되어 있는 MAC 주소는 전 세계에 하나밖에 없는 고유한 값이다.
예를들어 내 컴퓨터의 MAC 주소는 98:24:01:6E:09:5B 또는 98-24-01-6E-09-5B 로 표현 될 수 있다. (.. 물론 아무렇게나 적은 가짜 MAC 주소다 )
여기서 앞부분 98-24-01 상위 24비트는 제조업체 코드이고 뒷부분 6E-09-5B 하위 24비트는 제조업체 내부 코드이다.
NIC(Network Interface Controller)란 NIC은 컴퓨터를 네트워크에 연결하여 통신하기 위해 사용하는 하드웨어 장치이다. 흔히 우리가 네트워크 카드, 랜 카드로 부르는 것이 NIC 이다.
스위칭
네트워크 스위치가 데이터 패킷 내 포함된 주소 정보에 따라 해당 입력 패킷을 해당 출력 포트에 빠르게 접속 시키는 기능을 스위칭이라고 한다. 쉽게 설명하자면 네트워크 스위치가 수행하는 프레임 전송을 스위칭이라고 한다.
네트워크 스위치 란 네트워크 스위치는 L2 (제 2계층, 데이터 링크 계층)에서 사용하는 네트워크 기기로 LAN 케이블을 통해 컴퓨터를 연결한다. (.. 레이어(Layer)는 계층을 의미하고 해당 계층의 장비는 해당 계층에서 사용하는 프로토콜을 주고 받는다고 이해하면 쉽다) 네트워크 스위치는 프레임이 들어온 LAN 포트 번호와 그 프레임의 출발지 MAC 주소를 테이블로 만들어 일정 기간 동안 기억하며 불필요한 프레임 전송을 막고 이더넷 네트워크 통신의 효율을 향상 시키는 역할을 한다. 이때 LAN 포트 번호와 출발지 MAC 주소의 테이블을 MAC 주소 테이블이라고 한다.
MAC 주소
포트
A
1
B
2
C
3
< MAC 주소 테이블 >
IP (Internet Protocol)
IP는 전송 계층 (제 4계층)으로부터 받은 데이터(세그먼트)에 IP 헤더를 붙여 패킷으로 만드는 역할을 한다. IP헤더에는 여러 필드 값(버전,헤더길이,프로토콜 등), 출발지 IP주소, 도착지 IP주소가 들어간다.
패킷 구조
IP는 IP 주소라는 32비트로 된 식별번호를 사용하여 컴퓨터를 식별한다.
IP주소는 8비트 마다 점( . )으로 구분하고 10진수로 표기한다. IP주소는 네트워크 분리 및 구분을 위해 서브넷 마스크라는 32비트로 된 값과 세트로 사용한다. 또한 IP주소는 서브넷 마스크로 분할된 네트워크부와 호스트부로 구성되어 있다. 네트워크부는 네트워크 자체를 나타내고, 호스트는 해당 네트워크에 연결되어 있는 단말을 나타낸다. 서브넷 마스크는 연속된 1의 값이나 연속된 0의 값만 가질 수 있는데 이때 1의 값을 가지는 부분은 네트워크 부이고, 0의 값을 가지는 부분이 호스트부이다.
예를들어 IP 주소가 192.168.1.1 이고 서브넷 마스크가 255.255.0.0 이라고하자.
서브넷 마스크를 2진수로 나타내면 11111111.11111111.00000000.00000000 이다. 여기서 서브넷 마스크가 1이 되는 부분이 네트워크부 이기 때문에 192.168. 이 네트워크 부이고 1.1 부분은 서브넷 마스크가 0인 부분이기 때문에 호스트부이다. 서브넷 마스크의 1의 개수로 IP 주소를 간편하게 나타내면 192.168.1.1/16 이 된다.
만약 서브넷 마스크가 255.255.255.0 이라면 네트워크부는 192.168.1. 까지가 되고 나머지 1이 호스트부가 된다.
서브넷 마스크를 사용하는 이유 서브넷 마스크를 사용하는 이유는 IP 주소 자체가 개수가 제한되어 있고, 네트워크를 효율적으로 분배하기 위해서이다. 서브넷 마스크 원리는 서브네팅을 찾아보면 된다. ( ..서브넷 마스크 계산법을 찾아봐야한다)
라우팅
라우팅이란 라우터가 네트워크에서 패킷을 목적지까지 최적의 경로를 선택하는 과정이다.
라우터 란 라우터는 각 독립된 네트워크들을 연결할 때 L3(제 3계층, 네트워크 계층)에서 사용하는 네트워크 기기이다. L3 장비이기 때문에 패깃을 전송한다.
라우터는 라우팅 테이블을 이용하여 패킷을 전송한다. 라우팅 테이블은 목적지 네트워크와 목적지 네트워크로 가기 위해 보내야할 곳의 IP주소(넥스트 홉, next hop)로 구성되어 있다. 넥스트 홉이란 패킷이 목적지 네트워크까지 가기위해 도달하는 다음 라우터를 의미한다.
패킷이 목적지까지 가는데 거치는 라우터 개수를 홉 수(hop count) 라고 한다.
라우터는 패킷을 받으면 해당 패킷의 목적지 IP 주소와 라우팅 테이블의 목적지 네트워크를 대조하여 해당 IP주소가 있으면 패킷을 전송하고 없으면 패킷을 폐기한다.
라우팅에는 정적 라우팅과 동적 라우팅이 존재한다.
정적 라우팅
정적 라우팅이란 수동으로 라우팅 테이블을 만드는 방법
목적지 네트워크와 넥스트 홉을 하나하나 설정
정적 라우팅은 네트워크를 구성하는 모든 라우터에 대해 라우팅 설정이 필요
설정을 알기 쉽고 관리하기 쉽기 때문에 소규모 네트워크 환경에서 주로 사용
동적 라우팅
동적 라우팅이란 인접하는 라우터들이 라우팅 정보를 서로 교환하여 라우팅 테이블을 자동으로 만드는 방법
라우팅 정보를 교환하기 위한 프로토콜을 라우팅 프로토콜이라고 함
네트워크 환경의 변화대응과 장애 내구성 향상이 가능하기 때문에 중간부터 대규모 네트워크 환경에서 주로 사용
ARP (Address Resolution Protocol)
ARP는 MAC 주소와 IP 주소를 협조하면서 이용할 수 있도록 물리와 논리의 다리 역할을 한다.
즉, 물리적인 주소인 MAC 주소와 논리적인 주소인 IP 주소를 대응 시키는 역할을 하는 것이다.
네트워크 통신을 하기 위해서는 제 3계층으로부터 받은 패킷을 프레임으로 만들어 케이블로 흘려보내야 하는데 이때 출발지 MAC 주소는 자기 자신의 NIC에 쓰여 있는 MAC 주소라서 알 수 있지만 목적지 MAC 주소는 알 수가 없다. 이때 ARP를 이용하여 IP 주소로부터 MAC 주소를 구할 수 있다.
과정은 ARP request-> ARP reply -> ARP 테이블 등록 순이다.
동일 네트워크 상에서는 수집된 ARP 테이블을 참고하여 프레임을 만든다. 다른 네트워크 간 통신은 기본 게이트웨이의 MAC 주소를 ARP에서 조회하여 목적지 MAC 주소로 등록한다.
기본게이트웨이는 자신 이외의 네트워크로 갈 때 사용하는 출구가 되는 IP 주소이다. 보통 방화벽이나 라우터의 IP 주소가 기본 게이트웨이가 되는 경우가 많다.
IP 주소는 목적지까지 바뀌지 않지만 MAC 주소는 NIC을 경유할 때 마다 바뀐다.
TCP/UDP
TCP(Transmission Control Protocol)
TCP는 전송 제어 프로토콜로 IP와 함께 TCP/IP로 불리며 제 4계층(전송 계층)에서 사용되는 프로토콜이다.
TCP는 데이터를 송신할 때 마다 확인 응답을 주고 받는 절차가 있어서 통신의 신뢰성을 높인다.
웹이나 메일, 파일 공유 등과 같이 데이터를 누락시키고 싶지 않은 서비스에 주로 사용된다.
UDP(User Datagram Protocol)
UDP는 TCP와 함께 데이터 그램으로 알려진 단문 메시지를 교환하기 위해 사용하는 프로토콜이다.
테이터만 보내고 확인 응답과 같은 절차를 생략할 수 있으므로 통신의 신속성을 높인다.
주로 DNS, VoIP 등에 사용 된다.
TCP 와 UDP
TCP 와 UDP 모두 포트 번호로 서비스를 식별한다.
두 프로토콜을 구분하는 주요한 차이는 통신의 신뢰성이냐 신속성이냐이다.
애플리케이션 데이터에 TCP 또는 UDP 헤더를 추가하여 TCP 세그먼트나 UDP 세그먼트가 만들어진다.
포트 번호
포트 번호는 컴퓨터 안에서 작동하는 애플리케이션을 식별하기 위해 사용하는 숫자이다. 포트 번호는 0~65535(16비트 분)까지 숫자로 범위에 따라 용도가 정해져 있다. 포트 번호는 세그먼트를 만들 때 헤더에 출발지 포트와 목적지 포트로 들어간다.
0~1023 : 잘 알려진 포트(well-known port) 라고 해서 웹 서버나 메일 서버 등 일반적인 서버 소프트웨어가 서비스 요청을 대기할 때 사용된다.
1024~49151 : 등록된 포트(registered port)라고 해서 제조업체의 독자적인 서버 소프트웨어가 클라이언트 서비스 요청을 대기할 때 사용된다.
49152~65535 : 동적 포트(dynamic port)로 서버가 클라이언트를 식별하기 위해 사용된다. (클라이언트에서 서버에 대해 요청을 보낼 때 출발지 포트로 랜덤으로 지정해서 보낸다.)
NAT 와 NAPT
NAT 와 NAPT 는 기업이나 가정의 LAN 에서 사용하는 프라이빗 IP 주소를 인터넷에서 사용하는 글로벌 IP 주소로 변환하는 기술이다.
NAT(Network Address Translation)
NAT 는 프라이빗 IP 주소와 글로벌 IP 주소를 일대일로 연결하여 변환한다. 하나의 프라이빗 IP 주소와 하나의 글로벌 IP 주소를 연결하는 것이다. 주로 서버를 인터넷에 공개할 때 사용한다.
LAN 에서 인터넷으로 연결할 때는 출발지 IP 주소를 변환한다. 반대로 인터넷에서 LAN 으로 연결할 때는 목적지 IP 주소를 변환한다.
NAPT(Network Address Port Translation)
NAPT 는 프라이빗 IP 주소와 글로벌 IP 주소를 n 대 1로 연결하여 반환한다. NAPT 는 LAN 에서 인터넷에 엑세스 할 때 출발지 IP 주소 뿐만 아니라 출발지 포트 번호도 같이 반환함으로써 n 대 1 변환을 한다.