이 때 특수 문자가 반드시 들어가야 한다든지 특정 특수 문자는 입력이 불가능 하다든지와 같이 유효성 검사를 할 때 정규 표현식이 요긴하게 사용된다.
또한 텍스트에서 특정 정보나 패턴을 찾을 때 혹은 단어나 데이터 등을 변환할 때에도 정규 표현식을 사용할 수 있다.
간혹 정규 표현식을 사용하면 알고리즘 문제 등도 쉽게 해결되는 경우도 있다.
정규 표현식도 결국 개발자(정규표현식은 개발자 이외에도 자료를 다루는 사람 등도 해당된다.)의 생산성이나 유지보수에 있어서 좋기 때문에 사용한다고 보면 된다 :)
정규 표현식(Regular expression) 이란
정규 표현식은 정규식, Regex 으로도 많이 부르는데 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다.
한글로 표현하면 뜻이 더 어렵게 느껴지는데 영어 그대로 보자면 규칙적인 것, 일종의 패턴을 표현하는 언어라고 보면 된다.
정규 표현식은 대부분의 프로그래밍 언어나 텍스트 편집기(Intellj, visual studio code ...), OS(Unix/Linux, Mac, Windows) 에서 사용할 수 있다.
정규 표현식의 역사
정규 표현식은 1956년 스티븐 클레이니가 정규 집합(regular set)이라는 자신의 수학적 개념을 이용하여 정규 언어를 기술한 것을 기원으로 보고 있다. 여러 형태의 정규 표현식이 유닉스 프로그램에 사용되었고, 이후에 정규 표현식이 POSIX에 표준으로 인정 되었다.
POSIX의 정규 표현식도 다시 Basic 과 Extended 로 나뉘어 진다.
POSIX(Portable Operating System Interface X, x는 유닉스 호환 운영체제에 보통 x가 붙는 것에서 유래) 란
POSIX는 이식 가능 운영체제 인터페이스라는 뜻으로 서로 다른 UNIX OS의 공통 API를 정리하여 이식성 높은 유닉스 응용 프로그램을 개발하기 위한 목적으로 IEEE가 책정한 애플리케이션 인터페이스 규격이다. 즉, UNIX OS 간에 호환이 가능하도록 기준을 마련한 것으로 이해하면 된다.
1980년대에 POSIX의 정규 표현식을 확장한 Perl의 정규 표현식이 등장했으며, 이 또한 PCRE (Perl Compatible Regular Expressions)로 정리되며 많은 프로그래밍 언어에서 사용된다.
정규 표현식은 하나의 갈래로 이어져 확장되는게 아니라 기본적인 체계는 비슷하면서도 사소하게 다른 형태로 나뉘어져 있다.
그래서 정규 표현식은 프로그래밍 언어마다 문법이 조금씩 다르다.
하지만 또 그렇게 큰 차이는 없어서 언어 별로 정규 표현식을 사용하는데 어려움은 없지만 다량의 텍스트를 다룰 때는 실수를 할 수 있는 확률이 높아 주의할 필요가 있다. 때문에 자신이 사용하는 언어의 정규 표현식을 확인은 하고 사용하는게 좋다.
정규 표현식 문법
패턴 구분자
정규 표현식의 패턴이 달라질 경우 패턴을 구분하는 문자인데 보통은 슬래쉬(/)로 정규 표현식을 감싸준다.
"보통은" 이라고 말한 이유는 꼭 슬래쉬(/)가 아니어도 되기 때문이다.
예를들어 아래 처럼 해쉬(#) 나 (%) 등 특수문자 중에 공백이 아닌 문자나 역슬래쉬(\)를 제외하고는 아무거나 사용이 가능하다.
/^[0-9]*$/
#^[0-9]*s#
%^[0-9]*s%
메타 문자
정규 표현식에서 일정한 의미를 가지고 사용되는 특수문자를 메타 문자라고 한다.
^ : 문자열의 시작
$ : 문자열의 종료
. : 임의의 한 문자
| : or 을 의미
[] : 문자 클래스. 문자 클래스 안에서 ^ 는 not 을 의미하고 - 는 범위를 의미함
? : ?의 앞 문자가 없거나 하나 있음
+ : +의 앞 문자가 하나 이상 있음
* : *의 앞 문자가 0개 이상 있음
{n} : {n}의 앞 문자가 정확히 n개 있음
{n,} : {n}의 앞 문자가 n 번 이상 있음
{n,m} : 앞 문자가 n개 이상 m개 이하로 있음
() : 연산자의 범위와 우선권을 정의할 수 있음
\s : 공백 문자
\b : 문자와 공백 사이를 의미
\d : 숫자 [0-9]와 동일
\t : 탭문자
\w : 밑줄(_)을 포함한 영숫자 문자로 [A-Za-z0-9_]와 동일
* 문자 이스케이프는 대문자로 적으면 반대를 의미한다.
패턴 변경자
패턴 구분자가 끝나면 그 뒤에 쓰는 것으로, 패턴에 일괄적으로 변경을 가할 때 사용한다.
g: global을 의미하며 문자열 내의 모든 패턴을 찾음 (^ 를 문서의 처음에 $ 를 문서의 끝에 매치되게 변경)
i : ignore case를 의미하며 대소문자를 구별하지 않음
m : Multi line을 의미하며 문자열에 줄바꿈이 있더라도 패턴을 찾음
s : 문자열에 개행 문자(\n)도 포함하여 패턴을 찾음
x : 공백 문자를 무시함
자주 사용되는 정규 표현식
숫자 : ^[0-9]*$
영문자: ^[a-zA-Z]*$
유니코드 한글: ^[가-힣]*$
언급했듯이 프로그래밍 언어 마다 조금씩 지원하는 정규 표현식 문법이 다르기 때문에 이정도의 기본 정도만 익혀두고 자기가 사용하는 언어의 정규 표현식을 찾아 따로 확인을 해야한다.
어차피 대부분 정규 표현식을 자주 까먹기 때문에 보통은 정규 표현식을 작성할 때 마다 다시 확인하는 경우가 많다. (나만 그런가?)
하지만 정규 표현식을 잘 익혀두면 유용하게 사용하는 경우가 많아서 한 번쯤은 공부하고 정리하는게 필요한 부분이다.
Node.js 로 프로젝트를 진행하다 보면 필수적으로 npm 사용하게 된다. 당연히 쓰다보니 당연해진 NPM이 뭔지는 알고 사용하자.
npm 이란
npm 이란 노드 패키지 매니저 (Node Package Manager)를 의미한다. npm은 자바스크립트 런타임 환경인 Node.js 의 기본 패키지 관리자 역할을 한다. 그래서 npm을 통해 패키지 (package) 또는 모듈 (module) 이라고 불리는 자바스크립트 소프트웨어를 자신의 프로젝트에 설치할 수 있다. 또한 npm을 통해 자신의 프로젝트에서 사용 중인 패키지들의 버전 업데이트도 관리할 수 있다.
npm의 구성
npm은 다음과 같이 3가지로 구성되어 있다.
npm 웹사이트
CLI (Command Line Interface)
저장소
npm 웹사이트
npm 웹사이트 는 패키지를 찾을 수 있다. 보통 구글에서 npm <패키지 이름> 을 검색하면 npm에서 해당 패키지의 저장소 페이지가 나온다.
CLI
npm은 터미널에서 CLI를 통해 작동시킬 수 있다.
예를들어 npm init -y 을 통해 package.json 파일을 만들어 프로젝트를 시작할 수 있고, npm install <패키지 명> 으로 해당 프로젝트에서 패키지를 설치할 수도 있다.
저장소
npm에는 패키지들을 모아놓은 공개 저장소가 존재한다. 계정을 업그레이드 시키면 비공개 저장소도 사용이 가능하다.
개발을 하다보면 REST API 를 많이 사용하게 되는데 정말 내가 진짜 REST API 를 사용하고 있는가 다시한번 생각해 볼 수 있는 좋은 자료가 있어서 참고하여 나름대로 정리해 보았다.
REST API (Representational State Transfer Application Programming Interface) 란
REST API 는 REST 아키텍쳐를 스타일을 따르는 API로 여기서 REST 란 분산 하이퍼미디어 시스템을 위한 아키텍쳐를 의미한다.
REST는 HTTP 창시자 중 한 명인 로이 필딩(Roy Fielding)의 박사학위 논문에서 최초로 소개된 개념으로 웹과의 호환성을 유지하면서 웹의 장점을 최대한 활용할 수 있는 아키텍쳐를 제시하기 위해 만들어 졌다.
(.. 잘 설계된 웹을 잘 사용하라고 아키텍쳐까지 발표했지만 여전히 어렵다.)
REST의 특징
그렇다면 REST는 어떤 아키텍쳐인가 알기 위해 특징을 살펴보면 다음과 같다.
Client-Server 구조
REST 서버가 API 를 제공하고, 클라이언트는 사용자 인증이나 컨텍스트(세션, 로그인 정보) 등을 직접 관리하고 책임 지는 구조이다.
Stateless (무상태성)
REST 는 Stateless 즉, 상태를 유지하지 않는 특징을 가지는데 상태를 유지하지 않는 다는 것은 HTTP 세션이나 쿠키 같은 상태 정보를 저장하지 않는 다는 것을 의미한다. REST 서버는 단지 클라이언트의 요청만 처리할 뿐이라 구현이 단순하다.
Cache (캐시)
REST는 HTTP라는 기존 웹 표준을 그대로 사용하기 때문에 HTTP의 캐시 기능을 사용할 수 있다. 애초에 REST가 웹과의 호환성을 고려하여 만들어 졌기 때문에 당연하다고도 볼 수 있다. 예를들어 Last-Modified 태그 등을 사용하여 컨텐츠에 변화가 없으면 클라이언트가 캐싱해놓은 값을 사용하여 서버에 불필요한 트랜젝션 을 발생하지시키지 않아 서버 자원을 효율적으로 사용할 수 있다.
Layered System (계층형 시스템)
REST 서버는 다중 계층으로 구성이 가능하여 HTTP 프로토콜 기반의 로드 밸런서나 SSL (암호화 계층)을 추가할 수 있다.
Uniform Interface (일관성 있는 인터페이스)
REST 는 URI 로 지정한 리소스에 대해 일관성 있는 인터페이스를 제공함으로써 클라이언트와 서버가 독립적인 진화가 가능하다.
진화라는 말이 어색하지만 독립적인 진화라는 말은 쉽게 설명하면 서버가 변경되어도 클라이언트가 따로 업데이트를 할 필요가 없다는 것이다. 예를들어 웹 표준을 잘 지키고 있는 웹 브라우저를 생각하면 된다. 개발자가 서버를 아무리 변경해도 해당 서버에 접속하는 클라이언트는 웹 브라우저를 업데이트할 필요가 없다.
Uniform Interface 의 원칙
로이 필딩은 현재 REST API 라고 주장하는 API 들이 진짜 REST 가 아니며 제대로 REST 의 원칙을 지키거나 HTTP API 와 같은 이름을 사용하라고 말한다.
( .. 자신이 만든 REST 의 원칙을 제대로 안지키면서 REST 라고 떠들고 다니니 답답한 모양이다. )
여기서 로이 필딩이 말하는 REST의 원칙은 Uniform Interface 의 원칙을 의미한다.
Identification of resource (자원의 식별)
말 그대로 자원을 식별할 수 있어야 한다는 원칙인데, 쉽게 생각하면 REST를 구현하기 위해 설계하는 URI 를 생각하면 된다. URI를 통해 자원을 표현하는 것이다.
(.. 많은 개발자들이 URI 를 간단하고 직관적으로 설계하기 위해 고민하는 부분이다. )
Manipulation of resources through representations (표현을 통한 자원의 조작)
클라이언트가 어떤 자원을 가르키는 표현과 특정 메타데이터만 가지고 있다면 서버 상의 해당 자원을 변경 또는 삭제 할 수 있어야 한다는 원칙이다. REST API 를 설계할 때 자원에 대한 표현을 HTTP 메서드인GET,POST,PUT,DELETE 등을 사용하는 부분이라 생각하면 되겠다.
Self-descriptive messages (자기 서술적 메시지)
각 메시지에는 메시지를 어떻게 처리해야 하는지에 대한 충분한 정보를 포함해야한다는 원칙이다.
Uniform Interface 에서 주로 지켜지지 않는 원칙 중 하나로 URI 와 메서드, 메시지 포맷 등으로 REST API 를 쉽게 이해할 수 있어야 한다는 말이다.
예를 들면 HTTP 헤더의 미디어 타입의 정의를 들 수 있다. 미디어 타입의 정의 만으로 해당 메시지를 어떻게 처리해야 하는지 클라이언트가 알 수 있어야 한다.
Hypermedia As The Engine Of Application State(HATEOAS, 애플리케이션 상태에 대한 엔진으로서의 하이퍼미디어 )
이름만 들어도 거창한데 마찬가지로 Uniform Interface 에서 주로 지켜지지 않는 원칙 중 하나로 애플리케이션의 상태가 하이퍼미디어(하이퍼링크)를 통해 제공되어야 한다는 원칙이다.
예를 들어 링크 형태를 이용하면 서버에서 자원에 대한 URI를 변경하더라도 클라이언트에서는 코드 수정이 불필요 하다. 클라이언트는 서버에서 주어진 링크만 따라가면 되므로 서버는 링크를 동적으로 변경할 수 있기 때문이다.
REST API 를 사용해야 할까?
결국 REST API 에서 가장 많이 하는 고민.
개인적인 생각은 "사용하면 좋다" 이다.
다만 REST API 를 제대로 사용하는 것에 대해서는 고민을 해봐야할 것 같다.
REST API의 창시자인 로이 필딩은 다음과 같이 말했다고 한다.
"시스템 전체를 통제할 수 있다고 생각하거나, 진화에 관심이 없다면, REST에 대해 따지느라 시간을 낭비하지 마라."
(.. 명언이다. 실제로 REST 따지느라 시간 낭비를 많이 했었다 )
보통은 URI 나 HTTP 메서드 만 열심히 고민하고 REST API 를 사용했다고 한다.
많은 인싸(?) IT 회사들도 REST API 라고 언급 하지만 위의 원칙들을 다 지키지 않는 경우가 많다.
(.. 시스템 전체를 통제할 수 있는 범위 내에서 적당하게 사용하는 것 같다.)
마이크로소프트는 REST API 가이드라인까지 발표했지만 로이 필딩이 친히 그건 REST API 가 아니라고 까주었다. 중요한건 REST API 는 웹을 잘 활용할 수 있는 아키텍쳐이고, REST 의 원칙들을 자기 상황에 맞게 맞춰 사용하면 된다.
(.. 다만 REST 원칙을 모두 준수하지 않고 REST API 라고 명칭하는건 양심의 문제랄까)
REST API 설계 가이드
REST API 의 특징들은 웹에서 사용하는 기존 인프라를 그대로 활용하는 것들이라 대부분 자동적(?)으로 지켜진다. 그렇기 때문에 특별히 신경써야할 Uniform Interface 의 원칙에 따라 REST API 설계를 간단하게 해보자면 다음과 같다.
1. URI 는 자원을 표현
간단하면서도 직관적으로 만들고 명사를 사용한다.
예) /{colletions}/{id} -> /users/1
2. 표현을 통한 자원의 조작
HTTP 메서드 GET, POST, PUT, DELETE 등을 사용
예) get /users/1 : 아이디가 1 인 유저의 정보를 가져온다.
post /users/2: 아이디가 2인 유저를 추가 한다.
3. 자기 서술적 메시지
미디어 타입을 정의하고나서 IANA에 직접 등록하는 방법과 HTTP Link 헤더에 profile relation 으로 API 문서를 링크하는 방법이 있다.
예) Link : <https://example.com/docs/users>: rel="profile"
네트워크 기술이란 서버와 클라이언트의 정보가 오고 가는 다리 역할을 하는 기술의 총칭을 의미한다.
네트워크라는 말은 연결되어 있다라는 뜻으로 컴퓨터 네트워크는 데이터를 케이블에 실어 나르는 것을 의미한다.
(무선 LAN은 전파로 데이터를 실어 나른다.)
LAN (Local Area Network)
LAN 이란 기업이나 조직 등 비교적 좁은 범위 안에 존재하는 컴퓨터 네트워크를 의미한다.
LAN은 LAN 케이블을 이용하여 데이터를 전송하는 유선 LAN과 전파를 이용하여 데이터를 전송하는 무선 LAN으로 구분한다.
LAN 케이블 이란 LAN 케이블은 LAN을 연결 하기 위한 케이블
LAN 스위치 란 LAN 스위치는 LAN을 구성하기 위한 네트워크 기기
네트워크 작동 원리
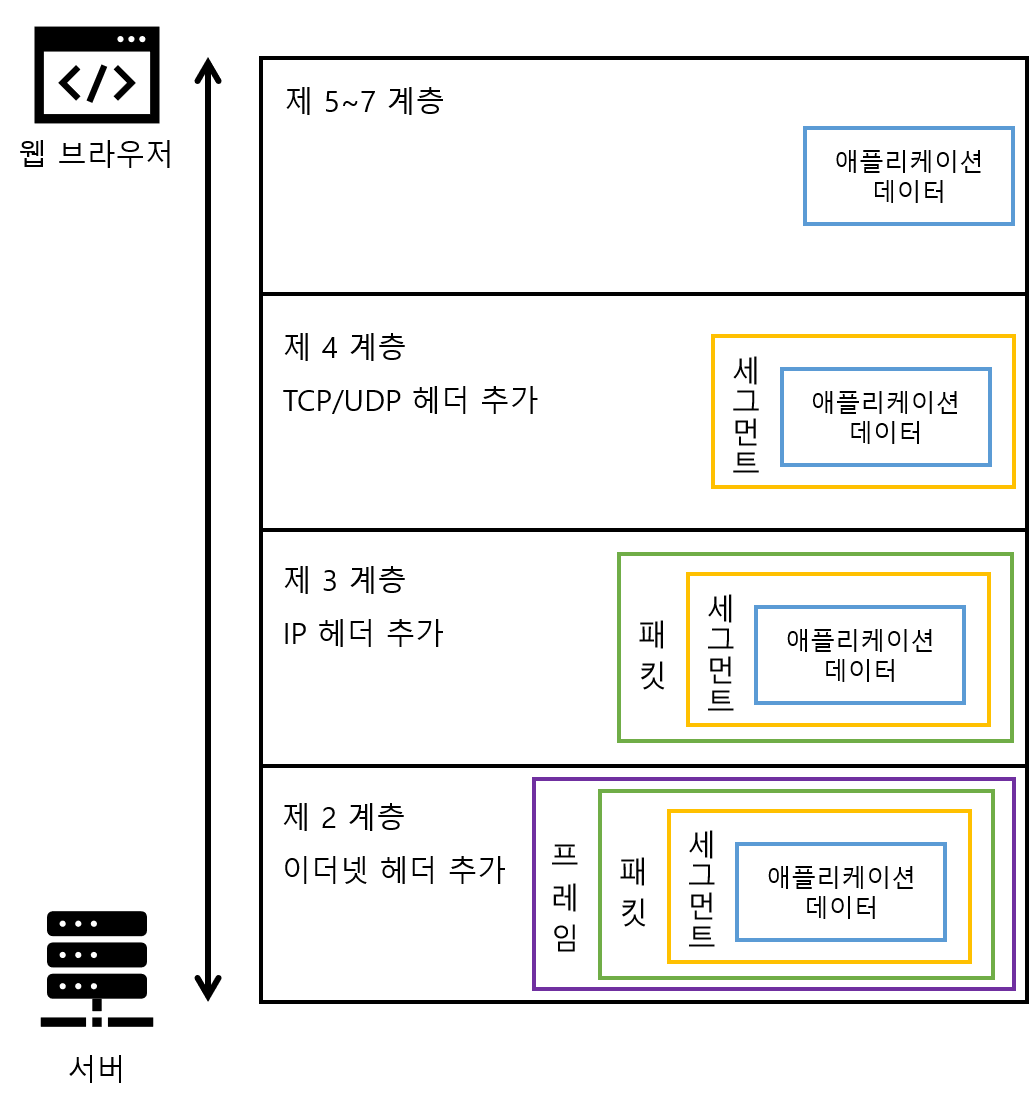
네트워크는 OSI 참조 모델을 바탕으로 작동한다. OSI 참조 모델은 국제표준화기구(ISO)가 컴퓨터 통신 기능을 계층 구조로 나눠서 정리한 모델로 일종의 통신 규칙 모음이라 생각하면 된다.
보통 OSI 7계층이라고 하는데 하위 계층(물리 계층) 부터 상위 계층(전송 계층)으로 구성된다.
OSI 7계층
제 1계층(물리 계층) : 네트워크 케이블의 재질이나 커넥터의 형식, 핀의 나열 방법 등 물리적인 요소를 모두 규정한다.
제 2계층(데이터 링크 계층) : 직접 연결된 기기 사이에 논리적인 전송로(데이터 링크)를 확립하는 방법을 규정한다.
제 3계층(네트워크 계층) : 동일 또는 다른 네트워크의 기기와 연결하기 위한 주소와 경로의 선택 방법을 규정한다.
제 4계층(전송 계층) : 데이터를 통신할 상대에게 확실하게 전달하는 방법을 규정한다.
제 5계층(세션 계층) : 데이터를 흘려보내는 논리적인 통신로(커넥션)의 확립과 연결 끊기에 대해 규정한다.
제 6계층(표현 계층) : 애플리케이션 데이터를 통신에 적합한 형태로 변환하는 방법을 규정한다.
제 7계층(응용 계층) : 애플리케이션 별로 서비스를 제공하는 방법을 규정한다.
OSI 참조 모델
프로토콜
응용 계층 (제 7계층)
애플리케이션 프로토콜 (HTTP 등)
표현 계층 (제 6계층)
애플리케이션 프로토콜 (HTTP 등)
세션 계층 (제 5계층)
애플리케이션 프로토콜 (HTTP 등)
전송 계층 (제 4 계층)
TCP / UDP
네트워크 계층 (제 3 계층)
IP / ICMP / ARP
데이터링크 계층 (제 2계층)
이더넷
물리 계층 (제 1계층)
이더넷
<OSI 참조 모델과 프로토콜 >
프로토콜
프로토콜이란 네트워크 통신을 위한 통신규칙을 의미한다.
프로토콜의 역할은 데이터의 캡슐화와 캡슐 해제화를 하는 것이다. 네트워크 통신에서 OSI 참조 모델의 계층을 넘어설 때마다 데이터를 캡슐에 넣거나 꺼낸다.
프로토콜 캡슐화 / 캡슐 해제화
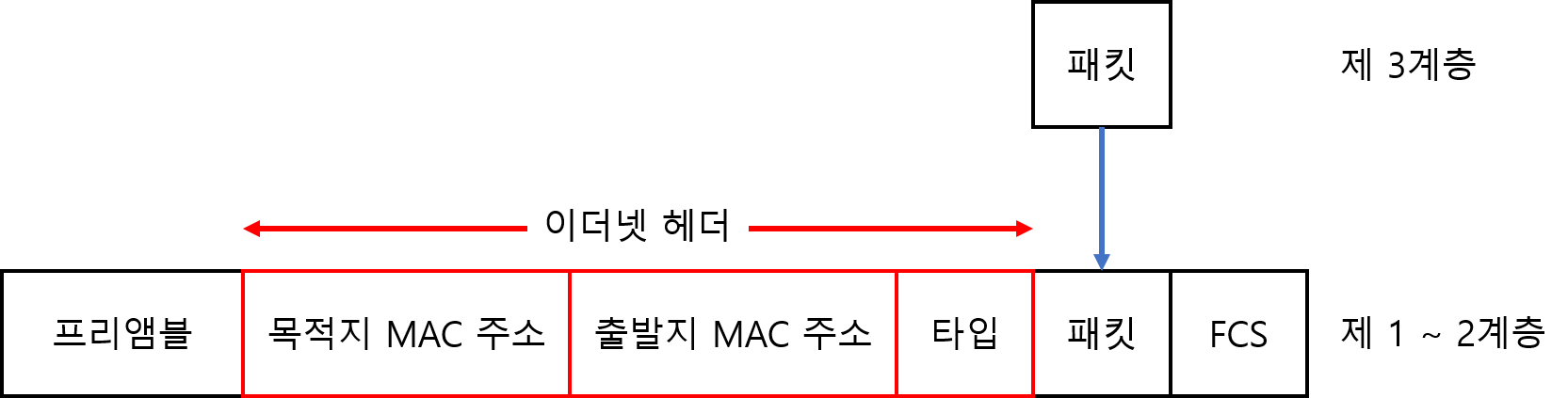
이더넷
이더넷은 OSI 제 1계층과 제 2 계층의 기술 규격이다. 유선 네트워크의 경우 거의 대부분이 이더넷을 사용한다.
이더넷은 네트워크 계층으로부터 받은 데이터(패킷)에 프레임의 처음을 나타내는 프리앰블(preamble)과 목적지(수신자)와 출발지(송신자)를 나타내는 헤더, 비트 오류체크에 사용하는 FCS(Frame Check Sequence)를 추가하여 프레임을 생성한다. 이더넷은 MAC 주소라는 48비트로 된 식별자를 사용하여 컴퓨터를 식별한다.
프레임 구조
MAC 주소
MAC 주소란 데이터링크 계층(제 2계층)에서 통신을 위해 사용되는 48비트로 된 식별자이다.
MAC 주소는 8비트 마다 하이픈( - ) 이나 콜론 ( : ) 으로 구분하여 16진수로 표기한다.
상위 24비트는 전기 및 전자관계 기술자 단체인 미국전기전자학회(IEEE)가 기기의 제조업체 별로 할당한 제조업체 코드(OUI, Organizationally Unique Identifier) 라고 하는데 해당 코드로 제조업체를 알 수 있다.
하위 24비트는 제조업체가 기기 별로 고유한 값을 할당한 코드이다.
NIC 에 할당되어 있는 MAC 주소는 전 세계에 하나밖에 없는 고유한 값이다.
예를들어 내 컴퓨터의 MAC 주소는 98:24:01:6E:09:5B 또는 98-24-01-6E-09-5B 로 표현 될 수 있다. (.. 물론 아무렇게나 적은 가짜 MAC 주소다 )
여기서 앞부분 98-24-01 상위 24비트는 제조업체 코드이고 뒷부분 6E-09-5B 하위 24비트는 제조업체 내부 코드이다.
NIC(Network Interface Controller)란 NIC은 컴퓨터를 네트워크에 연결하여 통신하기 위해 사용하는 하드웨어 장치이다. 흔히 우리가 네트워크 카드, 랜 카드로 부르는 것이 NIC 이다.
스위칭
네트워크 스위치가 데이터 패킷 내 포함된 주소 정보에 따라 해당 입력 패킷을 해당 출력 포트에 빠르게 접속 시키는 기능을 스위칭이라고 한다. 쉽게 설명하자면 네트워크 스위치가 수행하는 프레임 전송을 스위칭이라고 한다.
네트워크 스위치 란 네트워크 스위치는 L2 (제 2계층, 데이터 링크 계층)에서 사용하는 네트워크 기기로 LAN 케이블을 통해 컴퓨터를 연결한다. (.. 레이어(Layer)는 계층을 의미하고 해당 계층의 장비는 해당 계층에서 사용하는 프로토콜을 주고 받는다고 이해하면 쉽다) 네트워크 스위치는 프레임이 들어온 LAN 포트 번호와 그 프레임의 출발지 MAC 주소를 테이블로 만들어 일정 기간 동안 기억하며 불필요한 프레임 전송을 막고 이더넷 네트워크 통신의 효율을 향상 시키는 역할을 한다. 이때 LAN 포트 번호와 출발지 MAC 주소의 테이블을 MAC 주소 테이블이라고 한다.
MAC 주소
포트
A
1
B
2
C
3
< MAC 주소 테이블 >
IP (Internet Protocol)
IP는 전송 계층 (제 4계층)으로부터 받은 데이터(세그먼트)에 IP 헤더를 붙여 패킷으로 만드는 역할을 한다. IP헤더에는 여러 필드 값(버전,헤더길이,프로토콜 등), 출발지 IP주소, 도착지 IP주소가 들어간다.
패킷 구조
IP는 IP 주소라는 32비트로 된 식별번호를 사용하여 컴퓨터를 식별한다.
IP주소는 8비트 마다 점( . )으로 구분하고 10진수로 표기한다. IP주소는 네트워크 분리 및 구분을 위해 서브넷 마스크라는 32비트로 된 값과 세트로 사용한다. 또한 IP주소는 서브넷 마스크로 분할된 네트워크부와 호스트부로 구성되어 있다. 네트워크부는 네트워크 자체를 나타내고, 호스트는 해당 네트워크에 연결되어 있는 단말을 나타낸다. 서브넷 마스크는 연속된 1의 값이나 연속된 0의 값만 가질 수 있는데 이때 1의 값을 가지는 부분은 네트워크 부이고, 0의 값을 가지는 부분이 호스트부이다.
예를들어 IP 주소가 192.168.1.1 이고 서브넷 마스크가 255.255.0.0 이라고하자.
서브넷 마스크를 2진수로 나타내면 11111111.11111111.00000000.00000000 이다. 여기서 서브넷 마스크가 1이 되는 부분이 네트워크부 이기 때문에 192.168. 이 네트워크 부이고 1.1 부분은 서브넷 마스크가 0인 부분이기 때문에 호스트부이다. 서브넷 마스크의 1의 개수로 IP 주소를 간편하게 나타내면 192.168.1.1/16 이 된다.
만약 서브넷 마스크가 255.255.255.0 이라면 네트워크부는 192.168.1. 까지가 되고 나머지 1이 호스트부가 된다.
서브넷 마스크를 사용하는 이유 서브넷 마스크를 사용하는 이유는 IP 주소 자체가 개수가 제한되어 있고, 네트워크를 효율적으로 분배하기 위해서이다. 서브넷 마스크 원리는 서브네팅을 찾아보면 된다. ( ..서브넷 마스크 계산법을 찾아봐야한다)
라우팅
라우팅이란 라우터가 네트워크에서 패킷을 목적지까지 최적의 경로를 선택하는 과정이다.
라우터 란 라우터는 각 독립된 네트워크들을 연결할 때 L3(제 3계층, 네트워크 계층)에서 사용하는 네트워크 기기이다. L3 장비이기 때문에 패깃을 전송한다.
라우터는 라우팅 테이블을 이용하여 패킷을 전송한다. 라우팅 테이블은 목적지 네트워크와 목적지 네트워크로 가기 위해 보내야할 곳의 IP주소(넥스트 홉, next hop)로 구성되어 있다. 넥스트 홉이란 패킷이 목적지 네트워크까지 가기위해 도달하는 다음 라우터를 의미한다.
패킷이 목적지까지 가는데 거치는 라우터 개수를 홉 수(hop count) 라고 한다.
라우터는 패킷을 받으면 해당 패킷의 목적지 IP 주소와 라우팅 테이블의 목적지 네트워크를 대조하여 해당 IP주소가 있으면 패킷을 전송하고 없으면 패킷을 폐기한다.
라우팅에는 정적 라우팅과 동적 라우팅이 존재한다.
정적 라우팅
정적 라우팅이란 수동으로 라우팅 테이블을 만드는 방법
목적지 네트워크와 넥스트 홉을 하나하나 설정
정적 라우팅은 네트워크를 구성하는 모든 라우터에 대해 라우팅 설정이 필요
설정을 알기 쉽고 관리하기 쉽기 때문에 소규모 네트워크 환경에서 주로 사용
동적 라우팅
동적 라우팅이란 인접하는 라우터들이 라우팅 정보를 서로 교환하여 라우팅 테이블을 자동으로 만드는 방법
라우팅 정보를 교환하기 위한 프로토콜을 라우팅 프로토콜이라고 함
네트워크 환경의 변화대응과 장애 내구성 향상이 가능하기 때문에 중간부터 대규모 네트워크 환경에서 주로 사용
ARP (Address Resolution Protocol)
ARP는 MAC 주소와 IP 주소를 협조하면서 이용할 수 있도록 물리와 논리의 다리 역할을 한다.
즉, 물리적인 주소인 MAC 주소와 논리적인 주소인 IP 주소를 대응 시키는 역할을 하는 것이다.
네트워크 통신을 하기 위해서는 제 3계층으로부터 받은 패킷을 프레임으로 만들어 케이블로 흘려보내야 하는데 이때 출발지 MAC 주소는 자기 자신의 NIC에 쓰여 있는 MAC 주소라서 알 수 있지만 목적지 MAC 주소는 알 수가 없다. 이때 ARP를 이용하여 IP 주소로부터 MAC 주소를 구할 수 있다.
과정은 ARP request-> ARP reply -> ARP 테이블 등록 순이다.
동일 네트워크 상에서는 수집된 ARP 테이블을 참고하여 프레임을 만든다. 다른 네트워크 간 통신은 기본 게이트웨이의 MAC 주소를 ARP에서 조회하여 목적지 MAC 주소로 등록한다.
기본게이트웨이는 자신 이외의 네트워크로 갈 때 사용하는 출구가 되는 IP 주소이다. 보통 방화벽이나 라우터의 IP 주소가 기본 게이트웨이가 되는 경우가 많다.
IP 주소는 목적지까지 바뀌지 않지만 MAC 주소는 NIC을 경유할 때 마다 바뀐다.
TCP/UDP
TCP(Transmission Control Protocol)
TCP는 전송 제어 프로토콜로 IP와 함께 TCP/IP로 불리며 제 4계층(전송 계층)에서 사용되는 프로토콜이다.
TCP는 데이터를 송신할 때 마다 확인 응답을 주고 받는 절차가 있어서 통신의 신뢰성을 높인다.
웹이나 메일, 파일 공유 등과 같이 데이터를 누락시키고 싶지 않은 서비스에 주로 사용된다.
UDP(User Datagram Protocol)
UDP는 TCP와 함께 데이터 그램으로 알려진 단문 메시지를 교환하기 위해 사용하는 프로토콜이다.
테이터만 보내고 확인 응답과 같은 절차를 생략할 수 있으므로 통신의 신속성을 높인다.
주로 DNS, VoIP 등에 사용 된다.
TCP 와 UDP
TCP 와 UDP 모두 포트 번호로 서비스를 식별한다.
두 프로토콜을 구분하는 주요한 차이는 통신의 신뢰성이냐 신속성이냐이다.
애플리케이션 데이터에 TCP 또는 UDP 헤더를 추가하여 TCP 세그먼트나 UDP 세그먼트가 만들어진다.
포트 번호
포트 번호는 컴퓨터 안에서 작동하는 애플리케이션을 식별하기 위해 사용하는 숫자이다. 포트 번호는 0~65535(16비트 분)까지 숫자로 범위에 따라 용도가 정해져 있다. 포트 번호는 세그먼트를 만들 때 헤더에 출발지 포트와 목적지 포트로 들어간다.
0~1023 : 잘 알려진 포트(well-known port) 라고 해서 웹 서버나 메일 서버 등 일반적인 서버 소프트웨어가 서비스 요청을 대기할 때 사용된다.
1024~49151 : 등록된 포트(registered port)라고 해서 제조업체의 독자적인 서버 소프트웨어가 클라이언트 서비스 요청을 대기할 때 사용된다.
49152~65535 : 동적 포트(dynamic port)로 서버가 클라이언트를 식별하기 위해 사용된다. (클라이언트에서 서버에 대해 요청을 보낼 때 출발지 포트로 랜덤으로 지정해서 보낸다.)
NAT 와 NAPT
NAT 와 NAPT 는 기업이나 가정의 LAN 에서 사용하는 프라이빗 IP 주소를 인터넷에서 사용하는 글로벌 IP 주소로 변환하는 기술이다.
NAT(Network Address Translation)
NAT 는 프라이빗 IP 주소와 글로벌 IP 주소를 일대일로 연결하여 변환한다. 하나의 프라이빗 IP 주소와 하나의 글로벌 IP 주소를 연결하는 것이다. 주로 서버를 인터넷에 공개할 때 사용한다.
LAN 에서 인터넷으로 연결할 때는 출발지 IP 주소를 변환한다. 반대로 인터넷에서 LAN 으로 연결할 때는 목적지 IP 주소를 변환한다.
NAPT(Network Address Port Translation)
NAPT 는 프라이빗 IP 주소와 글로벌 IP 주소를 n 대 1로 연결하여 반환한다. NAPT 는 LAN 에서 인터넷에 엑세스 할 때 출발지 IP 주소 뿐만 아니라 출발지 포트 번호도 같이 반환함으로써 n 대 1 변환을 한다.
자바로 개발을 해보았다고 해도 스프링의 진입장벽은 높기 때문에 이러한 진입장벽을 그나마 낮춰주는 스프링부트가 존재한다.
(.. 그래서 스프링을 처음 공부하기 위해 스프링부트부터 선택하였다. 스프링 공부 서적으로 유명한 토비의 스프링 책만 보아도 스프링은 Top-down 으로 가야 할것 같다. )
스프링 프레임워크 란
스프링부트를 알기 위해서는 스프링 프레임워크부터 알아야한다.
스프링 프레임워크(이하 스프링)는 자바 기반 엔터프라이즈 애플리케이션 개발을 위한 포괄적인 인프라를 제공해주는 플랫폼이다.
스프링은 오픈소스 기반이며 쉽게 설명하면 엔터프라이즈 애플리케이션 개발을 편리하게 해주는 도구라고 생각하면 된다.
라이센스는 아파치 2.0 이다. ( .. 이게 스프링이 필수인 주요한 이유가 아닌가 싶다. )
엔터프라이즈 애플리케이션 이란 엔터프라이즈 애플리케이션은 이름 그대로 기업형 프로그램으로 자바에서는 JavaEE (Java Enterprise Edition)을 통해 개발되었다. JaveEE 는 JavaSE(Java Standard Edition)에 서버측 개발을 위한 기능이 더해진 자바 버전이라고 보면 된다. 스프링은 이런 JaveEE를 대체하기 위해 개발되었기 때문에 엔터프라이즈 애플리케이션 개발을 위한 플랫폼이라고 설명한다.
스프링의 역사
스프링은 2002년 로드 존슨이 최초로 개발하였다.
왜?
자바로 엔터프라이즈 애플리케이션을 개발하기 위해서 JavaEE가 사용되었는데 JavaEE에서 핵심적인 역할을 하는 것이 EJB 이다.
EJB는 엔터프라이즈 애플리케이션을 쉽게 작성할 수 있도록하는 목표를 가지고 있었지만 개발자들에게 EJB는 생각 보다 쉽지 않았다.
예를들어 소스코드 측면에서 EJB 관련 클래스를 반드시 사용해야 한다거나, 개발환경 측면에서 EJB 컨테이너를 사용해야 한다는 제약은 개발 생산성과 유지 보수성 저하와 테스트와 배포의 어려움을 가져왔다.
이러한 문제점들을 해결하고 엔터프라이즈 애플리케이션 개발을 더 쉽게 하기 위해 스프링이 탄생하였다.
EJB(Enterprise Java Beans) 란 EJB는 기업환경의 시스템을 구현하기 위한 서버측 컴포넌트 모델
스프링은 2004년 1.0 버전 출시 이후 계속 버전이 업데이트 되면서 2019년(현재 기준) 5.1 버전대 까지 등장하였다.
스프링의 특징
스프링의 특징은 하나하나 중요한 개념이고 가볍지 않은 내용이라 해당 특징들은 차차 공부하면서 알아가는게 좋을 것 같다. ( ..처음부터 이해도 되지 않을 뿐더러 지친다. )
처음엔 대략적으로 이런것들이 있구나만 알고 넘어가자.
스프링 구조
핵심 기술
POJO (Plain Old Java Object)
DI (Dependency Injection)
IoC (Inversion of Control)
AOP (Aspect Oriented Programming)
PSA (Potable Service Abstraction)
테스팅
mock objects
TestContext framework
Spring MVC Test
WebTestClient
통합
remoting
JMS
JCA
JMX
email
tasks
scheduling
cache
데이터 엑세스
transactions
DAO support
JDBC
ORM
Marshaling XML
스프링MVC 와 스프링WebFlux
언어 (자바 이외 지원 언어)
Kotlin
Groovy
dynamic language
스프링부트 란
스프링부트를 알기위해 돌고 돌아 스프링부터 간략하게 살펴보았는데 드디어 스프링부트란 무엇인가 말할 수 있다! 스프링부트는 실행만 하면 스프링 기반의 상용화가 가능한 애플리케이션을 쉽게 만들기 위해 단독 실행을 가능하게 해주는 스프링 프로젝트이다.
즉, 스프링부트는 스프링을 쉽게 사용할 수 있도록 필요한 설정을 대부분 미리 세팅 해놓았다는 뜻이다.
ubuntu 에서 apt-get update 를 하고 나서 apt-get upgrade 및 install 시에 다음과 같은 에러가 발생한다.
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable) E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
에러 메세지를 읽어보면 /var/lib/dpkg/ 디렉토리를 다른 프로세스에서 사용 중이라 충돌이 일어난다는 것 같다.
안드로이드 스튜디오를 간만에 업데이트(3.4.2 버전)하고 새 프로젝트를 생성하고 빌드하다 보니 다음과 같은 에러가 발생하였다.
Error: Invoke-customs are only supported starting with Android O (--min-api 26)
무슨 에러인가 보았더니 역시나 친절한 안드로이드 스튜디오는 알려준다.
AGPBI: {"kind":"error","text":"Invoke-customs are only supported starting with Android O (--min-api 26)","sources":[{}],"tool":"D8"} > Task :app:mergeExtDexDebug FAILED FAILURE: Build failed with an exception. * What went wrong: Execution failed for task ':app:mergeExtDexDebug'. > Could not resolve all files for configuration ':app:debugRuntimeClasspath'. > Failed to transform artifact 'material.aar (com.google.android.material:material:1.1.0-alpha08)' to match attributes {artifactType=android-dex, dexing-is-debuggable=true, dexing-min-sdk=24} > Execution failed for DexingTransform: /Users/noah/.gradle/caches/transforms-2/files-2.1/37a0daf16d8ba7dc17296903cb0a1c4f/jars/classes.jar. > Error while dexing. The dependency contains Java 8 bytecode. Please enable desugaring by adding the following to build.gradle android { compileOptions { sourceCompatibility 1.8 targetCompatibility 1.8 } } See https://developer.android.com/studio/write/java8-support.html for details. Alternatively, increase the minSdkVersion to 26 or above.
고맙게도 해결방법까지 알려준다.
프로젝트를 생성할 때 이번에 변경된 안드로이드x 패키지를 사용하였는데 라이브러리 중에서 자바8 (JDK 8) 언어의 바이트코드를 의존성으로 가지고 있어 컴파일 옵션추가가 필요하다는 것 같다. ( Dex 쪽 문제인듯 싶다. )
원인 : 라이브러리의 JDK 버전 호환 문제
해결책 : 프로젝트 gradle 에서 android { ~ } 안에 다음과 같은 옵션 추가
데이터베이스 설계는 시스템 개발을 하기 위해 필수적이기 때문에 데이터베이스 설계가 어떻게 이루어지는지 알 필요가 있다.
데이터베이스 설계는 데이터 중복이 없어야 하며 필요한 데이터에 대한 정확한 분석이 필요하다.
데이터베이스가 제대로 설계되지 않으면 추후 확장이나 유지보수가 굉장히 어렵고, 설계를 바꾸는 작업도 비용이 많이 든다.
( ..데이터베이스 설계가 프로젝트의 백년대계를 좌지우지 한다고 해도 과장이 아니다. )
데이터베이스 설계 프로세스
데이터베이스 설계 프로세스를 살펴보면 가장 우선적으로 해야할 일은 프로젝트에 필요한 데이터를 파악하고 분석하는 일이다.
실제로 프로젝트를 진행하다 보면 데이터베이스 설계 자체 문제 보다는 프로젝트에 필요한 데이터에 대한 정의나 파악부터 미흡해서 어려움을 겪는 일이 많기 때문이다.
데이터에 대한 파악과 분석이 끝나면 아래의 그림과 같은 순서로 데이터 모델링을 진행된다.
< 데이터베이스 설계 프로세스 >
데이터 모델링이란
데이터 모델링이란 현실 세계의 어떠한 개념을 컴퓨터의 데이터베이스로 옮기는 변환 과정을 의미한다.
이러한 데이터 모델링을 과정에 따라 개념적, 논리적, 물리적 데이터 모델링으로 구분한다.
개념적 데이터 모델링
: 개념적 데이터 모델링은 데이터들의 구조도를 그리는 과정이다. 개념적 데이터 모델링을 할 때에는 개체-관계 모델(E-R Model, Entity-Relationship Model)을 많이 사용한다.
논리적 데이터 모델링
: 논리적 데이터 모델링은 데이터 모델을 선택하고 데이터 스키마를 결정하는 과정이다. 이 과정에서 관계 데이터 모델을 가장 많이 사용한다.
물리적 데이터 모델링
: 물리적 데이터 모델링은 논리적 데이터 모델링에서 선택한 데이터베이스 모델에 따라 데이터베이스 관리 시스템(DBMS)으로 물리적인 데이터베이스를 만들어내는 과정이다.
데이터 모델링 과정이 이름은 어렵게 구분해 놓았지만 단순하게 따져보면 데이터들의 관계를 구조화시켜서 그려보고, 어떤 데이터베이스 모델을 선택할지 결정해서 데이터를 어떤 형식(데이터 타입)으로 저장하고 어떤 제약조건을 적용할지 정한 다음 DBMS로 구현하는 것이다.
더 구체적으로 데이터 모델을 적용해서 설명하자면 개체-관계 모델을 이용하여 필요한 데이터들의 구조도를 그려보고, 관계 데이터베이스 모델에 따라 스키마를 결정하면 된다. 그리고 MySQL 같은 자신이 선택한 RDBMS 로 데이터베이스를 구축하면 된다.
개체-관계 모델이란
개체-관계 모델은 피터 첸(Peter Chen)이란 컴퓨터 박사가 1976년에 제안한 것으로, 개체-관계 다이어그램 (E-R 다이어그램)이라고도 한다. E-R 다이어그램은 데이터를 개념적으로 모델링한 결과물을 그림으로 표현하는 방법론으로 구성은 개체, 속성, 관계로 이루어져있다.
사각형, 마름모, 타원, 선 등을 이용하여 개체들의 일대일(1:1), 일대다(1:n), 다대다(n:m) 관계를 그림으로 표현한다.
사각형은 개체, 마름모는 개체 간의 관계, 타원은 개체나 관계의 속성을 나타낸다. 연결선(링크)는 각 요소를 연결하는 역할을 한다.
< ER 다이어그램 구성 요소 >
개체 (entity) : 독립된 하나의 개념적 존재로 RDBMS 에서는 하나의 테이블이라 생각하면 된다.
< 개체 >
약한 개체(weak entity) : 두 개체가 있을 때 독자적으로 존재할 수 없고, 종속되는 개체를 약한 개체라고 한다. 예를들어 고객과 구매내역이라는 개체가 있으면 두 개체는 구매라는 관계로 이어지고, 구매내역은 고객이라는 개체가 없으면 의미가 없는 것이기 때문에 고객 개체에 종속된다. 여기서 고객을 오너개체, 구매내역을 약한 개체라고 부른다. 일반적으로 오너 개체와 약한 개체는 일대다(1:n)의 관계를 가진다. ( 오너 개체와 약한 개체가 맺는 관계는 이중 마름모로 표현한다. )
< 약한 개체 >
속성(attribute) : 속성은 개체가 가지고 있는 고유의 특성이다. 속성들이 모여 하나의 개체가 된다. RDBMS에서는 레코드 부분이라 생각하면 된다. 속성에도 종류가 있는데 아래의 그림과 같이 상품 번호처럼 밑줄 그어진 속성은 키 속성으로 개체의 각 인스턴스를 식별하는 역할을 한다. 할인율 같은 경우는 단일 속성으로 하나의 값을 가지는 일반적인 속성이다. 판매가격 같은 경우는 다른 속성의 값에 따라 값이 유도되어 결정된다고 하여 유도 속성이라 한다. 판매처의 경우 다중 값 속성이라 하여 값이 여러개가 존재할 수 있는 속성이다. 상품마다 판매처는 여러 곳일 수 있기 때문에 다중 값 속성이 되는 것이다.
< 속성 >
관계(relationship) : 관계는 각각의 개체의 인스턴스들이 맺는 관계 유형에 따라 일대일(1:1), 일대다(1:n), 다대다(n:m) 으로 나누어진다.
< 일대일(1:1) 관계 >< 일대다(1:N) 관계 >
< 다대다(N:M) 관계 >
이 외에도 E-R 다이어그램으로 표현 가능한 다양한 방법들이 있다. 자신의 목적에 맞게 사용하면 되겠다.
관계 데이터 모델
논리적 데이터 모델링에서 사용되는 관계 데이터 모델은 하나의 개체에 대한 데이터를 릴레이션(테이블) 하나에 담아 데이터베이스에 저장한다. 계층형, 네트워크형에 비해 개체 간 관계 표현이나 데이터 검색, 삽입, 삭제, 수정 등 데이터 연산에 더 유리하고 이해하기 쉬워 관계 데이터 모델을 가장 많이 사용한다. 논리적 데이터 모델링에서는 관계 데이터 모델에 맞게 릴레이션을 정의하고 각 속성에 맞는 스키마를 지정하는 작업을 하게 된다.
( ..E-R 다이어그램을 관계 데이터 모델로 옮기는 작업이다 생각하자. )
1. 관계 데이터 모델 용어 정리
속성 : 열 또는 어트리뷰트(attribute) 라고 부르며, 테이블에서 필드에 해당하는 부분이다. 속성은 서로 다른 이름을 붙여서 구분한다.
튜플 : 릴레이션(테이블)의 행을 튜플(tuple)이라고 한다. 개체의 인스턴스를 의미하며, 테이블에서 레코드에 해당하는 부분이다.
도메인 : 속성 하나가 가질 수 있는 값의 모음을 의미한다. RDBMS에서는 데이터 타입을 생각하면 된다.
널 값 : 널(null) 값은 특정 속성에 해당 값이 없는 경우를 나타낸다. ( 숫자 0 or 공백은 그 자체를 값으로 보기 때문에 null 이 아니다. )
차수 : 하나의 릴레이션(테이블)에서 속성의 전체 개수를 릴레이션의 차수(degree)라고 한다. 테이블에서 필드의 개수라고 생각하면 된다.
카디널리티 : 카디널리티(cardinality) 는 하나의 릴레이션에서 투플의 전체 개수를 의미한다. 즉 하나의 테이블의 레코드수( 데이터 수) 라고 보면 된다.
2. 릴레이션(테이블)의 특성
튜플의 유일성 : 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다는 뜻이다. 즉, 테이블에서 레코드가 중복되지 않는다는 의미인데 이러한 특성을 만족시키기 위해서 키(key) 라고 부르는 값의 중복이 불가능한 속성을 넣는다.
튜플의 무의미한 순서 : 릴레이션에서 튜플의 순서는 무의미하다는 뜻이다. RDBMS는 사람이 알아보기 쉽게 테이블 형태로 순차적으로 데이터를 담아 보여주지만 데이터들의 순서는 사실 상관없다. 데이터베이스는 위치가 아닌 내용으로 검색되기 때문이다.
속성의 무의미한 순서 : 릴레이션에서 속성의 순서 또한 의미가 없다는 뜻이다. 튜플과 마찬가지로 사람이 알아보기 쉽게 지정한 속성을 순서대로 보여주지만 데이터베이스에서는 상관없는 부분이다. 데이터베이스에서는 속성도 위치가 아닌 속성의 이름으로 속성을 구별하기 때문이다. 따라서 속성의 이름을 어떻게 짓느냐가 더 중요할 수 있다.
속성의 원자성 : 속성의 원자성이라는 특성은 속성의 값은 하나의 값(원자 값)만 가질 수 있다는 뜻이다.
3. 키(key)
키는 관계 데이터 모델에서 제약조건을 정의한다.
슈퍼키(super key) : 슈퍼키는 유일성을 만족하는 속성을 의미한다. 유일성이라는 것은 키 값이 유니크(unique)하다는 것이며 유일성은 키가 갖추어야 하는 기본 특성이다. 쉽게 설명하자면 키가 되는 속성의 값에는 중복이 없다는 것이다.
후보키(candidate key) : 후보키는 유일성과 최소성을 만족하는 속성이다. 최소성은 해당 키 속성이 없으면 튜플을 구별할 수 없는 꼭 필요한 속성을 의미한다. 여러 속성이 키로 지정될 수 있기 때문에 슈퍼키 중에서도 단독으로 튜플을 구별할 수 있는 속성들만 후보키가 될 수 있다.
기본키(primary key) : 기본키는 후보키 중에 기본적으로 사용할 키로 선택한 속성을 의미한다. 널(null) 값을 가질 수 있는 속성은 기본키로 부적합하고, 값이 변경될 가능성이 적은 후보키가 기본키로 적합하다. 예를들어 아이디값이나, 회원번호 같은 값들이 기본키로 적합하다 볼 수 있다.
대체키(alternate key) : 대체키는 기본키로 선택되지 못한 후보키들이다.
외래키(foreign key) : 외래키는 다른 릴레이션의 기본키를 참조하는 속성이다. 외래키는 관계 데이터 모델에서 관계를 이어주는 핵심이라고 볼 수 있는데, 다른 릴레이션의 기본키 값을 참조하여 릴레이션을 서로 이어준다. 쉽게 생각하면 테이블끼리 이어주는 값이라 보면 되고, 외래키는 다른말로 참조키라고 하는데 이름 그대로 참조하는 기본키의 값 내에서 값을 가져야한다. (참조할 수 없는 값은 가질 수 없다.) 외래키는 기본키를 참조하기 때문에 중복 값을 가질 수 있고, 기본키의 값 내에서 값을 가져야 한다고 했지만 예외로 널(null) 값은 가질 수도 있다.
4. 관계 데이터 모델의 제약 조건
관계 데이터 모델을 사용할 때 지켜야하는 조건을 관계 데이터 모델의 제약조건이라고 한다. 개체 무결성 제약조건과 참조 무결성 제약조건이 있는데 각각 기본키와 외래키에 관한 제약조건이다. 이 조건들은 데이터를 정확하고 유효하게 유지하기 위해 지켜야하는 조건이다.
개체 무결성 제약조건 : 기본키를 구성하는 모든 속성은 널(null) 값을 가질 수 없다.
참조 무결성 제약조건 : 외래키는 참조할 수 없는 값을 가질 수 없다. ( 다만, 널(null) 값은 예외로 참조 무결성 제약조건을 위반한 것으로 보지 않는다.)