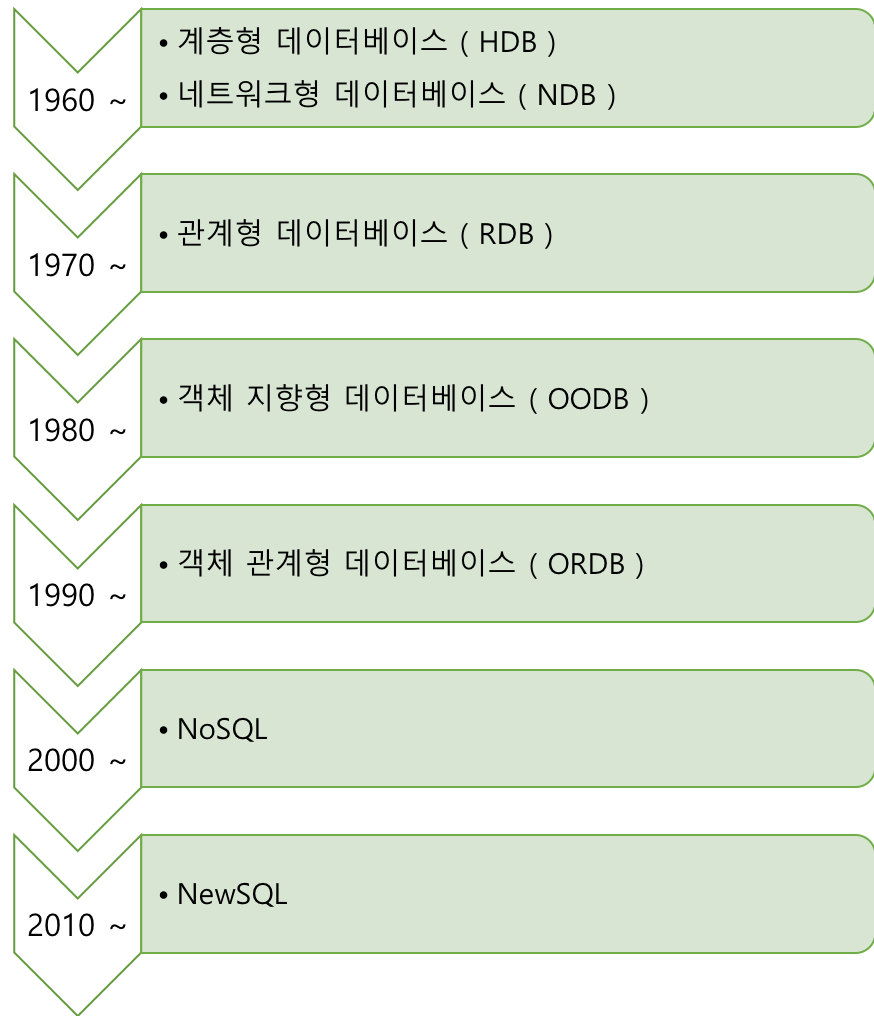
데이터베이스에 대해 정리하면서 데이터베이스 관리 시스템에 대해서도 정리하기는 했지만 DBMS의 내부 구성이 어떤지 어떻게 작동하는지에 대해서도 알아둘 필요가 있다.
2019/06/07 - [IT 정보 로그캣/데이터베이스] - [데이터 베이스] 데이터베이스란 ?
[데이터 베이스] 데이터베이스란 ?
우리는 자료와 정보라는 말을 많이 사용한다. 보통 두 단어를 혼동해서 많이 사용하는데 엄밀히 따지자면 각각 정의가 다르다. 자료(Data) 는 숫자, 영상, 단어 등의 형태로 된 의미 단위로 날것(raw)에 가깝다...
noahlogs.tistory.com
데이터 언어
데이터베이스 관리 시스템의 구성을 이해하기 위해 데이터 언어부터 살펴보자.
데이터베이스 관리 시스템을 사용하기 위해서는 데이터 언어(Data Language)를 사용해야한다.
보통은 데이터 언어라고하면 SQL을 의미한다고 생각하면 되는데 이러한 데이터 언어도 기능에 따라 개념이 나뉘어진다.
-
데이터 정의어(DDL, Data Definition Language) : 스키마를 정의하거나, 수정 또는 삭제하기 위해 사용하는 언어. 데이터 정의어로 정의된 스키마는 데이터 사전에 저장되고, 삭제나 수정이 발생하면 이 내용도 데이터 사전에 반영된다. Create, Alter, Drop 등이 있다.
-
데이터 조작어(DML, Data Manipulation Language) : 데이터의 삽입, 삭제, 수정, 검색 등의 처리를 요구하기 위해 사용하는 언어. Select, Insert, Delete, Update 등이 있다.
-
데이터 제어어(DCL, Data Control Language) : 내부적으로 필요한 규칙이나 기법을 정의하기 위해 사용하는 언어. Commit, Rollback, Grant, Revoke 등이 있다.
스키마(schema)란
스키마는 데이터베이스에 저장되는 데이터 구조와 제약조건을 정하는 것을 의미한다.
예를들어 데이터베이스는 데이터에 INT, CHAR 등의 데이터 타입을 지정한다거나, 중복된 값을 허용하지 않는 등의 제약조건을 지정할 수 있다.
데이터베이스 관리 시스템의 구성
데이터베이스 관리 시스템은 기능에 따라 크게 질의 처리기와 저장 데이터 관리자로 구성되어 있다.

질의 처리기(Query Processor)
질의 처리기는 사용자의 데이터 처리 요구를 해석하여 처리하는 역할을 한다.
-
DDL 컴파일러(DDL compiler) : 데이터 정의어로 작성된 스키마를 해석한다. 데이터베이스를 생성하거나, 스키마의 정의를 데이터 사전에 저장한다.
-
DML 프리컴파일러(DML precompiler) : 응용 프로그램에 삽입된 데이터 조작어를 추출하여 DML 컴파일러에 전달한다.
-
DML 컴파일러 (DML compiler) : 데이터 조작어 (삽입, 삭제, 수정, 검색) 요청을 분석하여 런타임 데이터베이스 처리기가 이해할 수 있도록 해석한다.
-
런타임 데이터베이스 처리기 (run-time database processor) : 저장 데이터 관리자를 통해 데이터베이스 접근하여 DML 컴파일러로 부터 전달받은 요청을 데이터베이스에서 실제로 실행한다.
-
트랜잭션 관리자(transaction manager) : 데이터베이스에 접근하는 과정에서 사용자의 접근 권한이 유효한지 검사하고, 데이터베이스 무결성을 유지하기 위한 제약조건 위반 여부를 확인한다. 회복이나 병행 수행과 관련된 작업도 한다.
컴파일러(compiler)란
컴파일러는 특정 프로그래밍 언어로 쓰여 있는 문서를 다른 프로그래밍 언어로 옮기는 프로그램을 말한다. 컴파일러가 우리가 작성한 고급 프로그래밍 언어는 컴퓨터가 이해할 수 있는 언어(기계어)로 변환해주어야 실행된다.
DBMS 에서도 마찬가지로 사용자가 작성한 데이터 언어가 수행될 수 있도록 컴파일러가 변환해주는 것이다.
저장 데이터 관리자(stored data manager)
저장 데이터 관리자는 디스크에 저장되어 있는 사용자 데이터베이스와 데이터 사전을 관리하고, 접근한다.
하지만 디스크에 저장된 데이터에 접근하는 것은 운영체제의 기본 기능이므로 저장 데이터 관리자는 운영체제의 도움을 받아 데이터베이스에 대한 접근을 수행한다.
데이터 사전(data dictionary)란
데이터 사전이란 시스템 카탈로그(system catalog)라고도 한다. 데이터 사전은 데이터베이스에 저장되는 데이터에 관한 정보를 저장한다.
데이터에 대한 정보를 의미하기 때문에 메타 데이터라고도 한다. 데이터 사전도 그냥 하나의 데이터베이스라고 생각하면 된다.
'IT 정보 로그캣 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 데이터베이스 설계 (0) | 2019.06.21 |
|---|---|
| [데이터베이스] 관계형 데이터베이스(RDB)란 ? (0) | 2019.06.07 |
| [데이터 베이스] 데이터베이스란 ? (0) | 2019.06.07 |